Uploading Profiles to WhyLabs
Collecting Profiles
Data ingestion in WhyLabs is done by uploading whylogs profiles to the platform, which are statistical summaries of the source data. The process of profiling data can be done offline and locally within a customer's environment. To upload the generated profiles to your project's dashboard, you will need to utilize an API key and explicitly write the profile to WhyLabs.
Once your WhyLabs credentials are configured, profiling your data with whylogs and sending the profile to WhyLabs can be as simple as:
import whylogs as why
from whylogs.api.writer.whylabs import WhyLabsWriter
profile = why.log(df).profile()
writer = WhyLabsWriter()
writer.write(file=profile.view())
If you want to know more about writing profiles to WhyLabs, please refer to the following example notebook in the whylogs GitHub repository:
Profile Management in WhyLabs
To understand how profiles are managed in WhyLabs, we need to first remind that:
- profiles are mergeable
- profiles have a dataset timestamp
An uploaded profile will be safely stored in WhyLabs, but how it is displayed in the dashboard depends on the project's configuration. For example, if the project was configured to have a daily/hourly/weekly frequency, profiles will be merged and displayed in your dashboard in a daily/hourly/weekly granularity, respectively.
For example, if 17 profiles were uploaded to an hourly project between 02:00 and 03:00, this information would be displayed throughout your dashboard as a single profile representing the statistical summary for the combination of the 17 profiles.
Integration Options
REST API
Most customers integrating with WhyLabs will opt to upload profiles via the mechanism built into the open source Whylogs library. Simply obtain an API key, plug it in, and you're ready to go.
Speed of data availability
Uploading a profile for any data timestamp, past and present, will typically become visible in the UI in under a minute (often just a few seconds).
S3
Some enterprise customers operate with very strict network egress rules blocking access to cloud based REST APIs. For such scenarios we offer the ability to pull profiles dumped to a blob store such as AWS S3. Contact us for more information!
Speed of data availability
Cross account blob store integrations currently have a one day turnaround for new profiles to be processed and visible in the UI.
Distributed Environment Logging (Spark/Flink/Kafka)
Depending on how you use whylogs in your environment you might have multiple machines in a distributed context generating profiles for the same dataset+time+segment. Whylogs profiles are easily mergable making it easy to reduce data egress volume prior to uploading. If profiles are not merged prior to upload, that's okay too! The whyLabs platform will merge them automatically.
For example, suppose a kafka topic is being profiled with whylogs using multiple consumers instances emitting a profile once an hour. Profiles will automatically merge and reflect changes throughout the day.
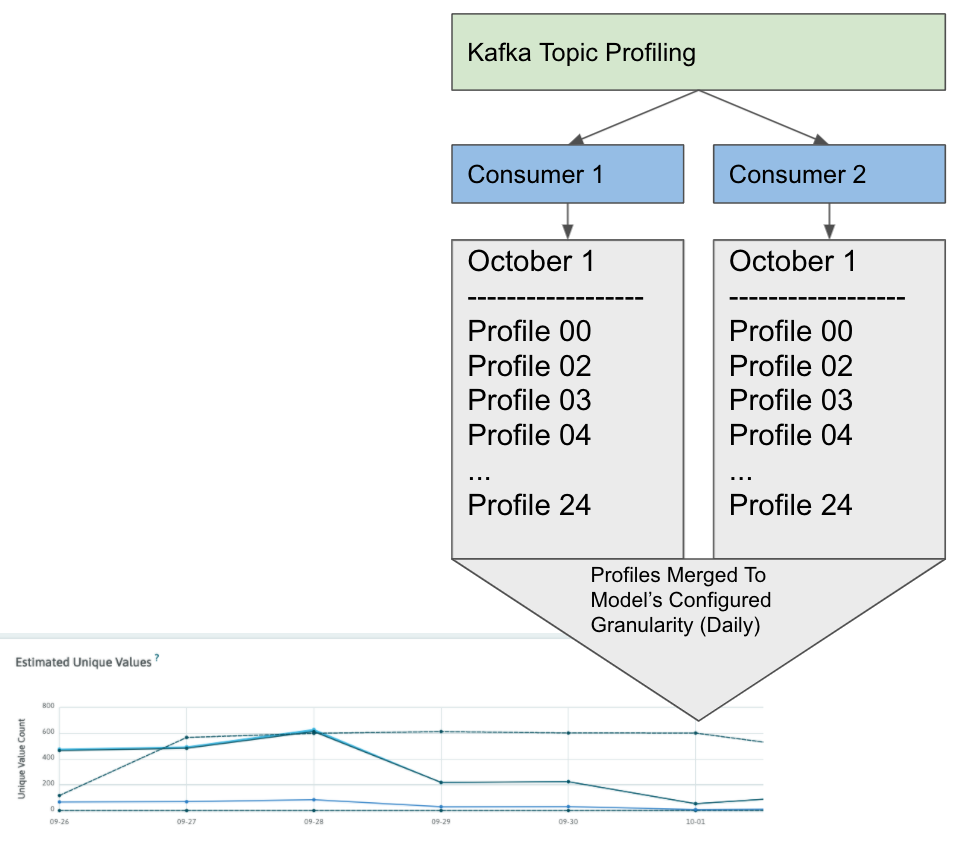
If you want to know more about uploading profile in a distributed environment using specific tools, check the respective documentation in the Integrations Section.
Batch upload transactions
Sometimes it's practical to upload multiple profiles in an all-or-nothing way, which is what the batch upload transactions API was designed to enable. In such a workflow, the user first initializes a transaction, stages multiple profiles for uploading and then commits the transaction. Only after the transaction is closed, all the staged profiles are ingested on the platform. If any of the uploads fails, the entire transaction gets aborted and no profiles are ingested.
Below you can see a transaction implementation presented on a use case with five batches of data, one per each day:
writer = WhyLabsWriter()
transaction_id = writer.start_transaction()
print(f"Started transaction {transaction_id}")
for i in range(5):
batch_df = list_daily_batches[i]
profile = why.log(batch_df)
timestamp = datetime.now(tz=timezone.utc) - timedelta(days=i+1)
profile.set_dataset_timestamp(timestamp)
status, id = writer.write(profile)
print(status, id)
writer.commit_transaction()
In case any of the profiles wasn't successfully uploaded, the writer.commit_transaction() call will throw an exception and the transaction will fail to commit.
Distributed batch upload transactions
Transactions are also supported in a distributed workflow using whylogs+PySpark implementation. Assuming that we have multiple Spark DataFrame objects defined and the whylogs[spark] module installed, we can facilitate the transaction in the following way:
# %pip install 'whylogs[spark]'
from whylogs.api.writer.whylabs import WhyLabsWriter
from whylogs.api.pyspark.experimental import collect_dataset_profile_view
from datetime import datetime, timezone, timedelta
writer = WhyLabsWriter()
transaction_id = writer.start_transaction()
print(f"Started transaction {transaction_id}")
for i in range(3):
profile = collect_dataset_profile_view(spark_dataframe)
timestamp = datetime.now(tz=timezone.utc) - timedelta(days=i+1)
profile.dataset_timestamp = timestamp
writer.write(profile)
writer.commit_transaction()
print(f"Committed transaction {transaction_id}")

