Segmenting Data
Overview
Sometimes, data subgroups can behave very differently from the overall dataset. When monitoring the health of a dataset, it’s often helpful to have visibility at the subgroup level to better understand how these subgroups are contributing to trends in the overall dataset. WhyLabs supports data segmentation for this purpose.
Data segmentation is done at the point of profiling a dataset via whylogs. Segmentation can be done by a single feature or by multiple features simultaneously. Upon uploading a segmented profile to WhyLabs, users will see each of their segments in the “Segments” section of the model dashboard within a particular model.
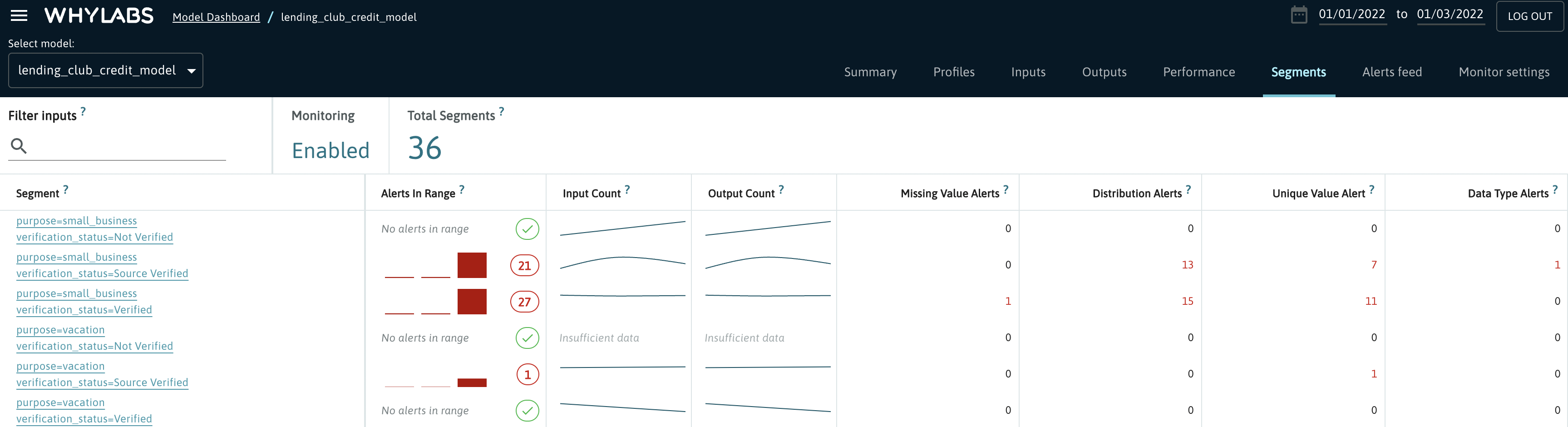
In the example above, data is segmented by the purpose and verification_status features. Upon clicking on one of these segments, users will be directed to the inputs view for this particular segment. The image below shows a segmented input view with purpose equal to “small_business” and verification_status equal to “Source Verified”.
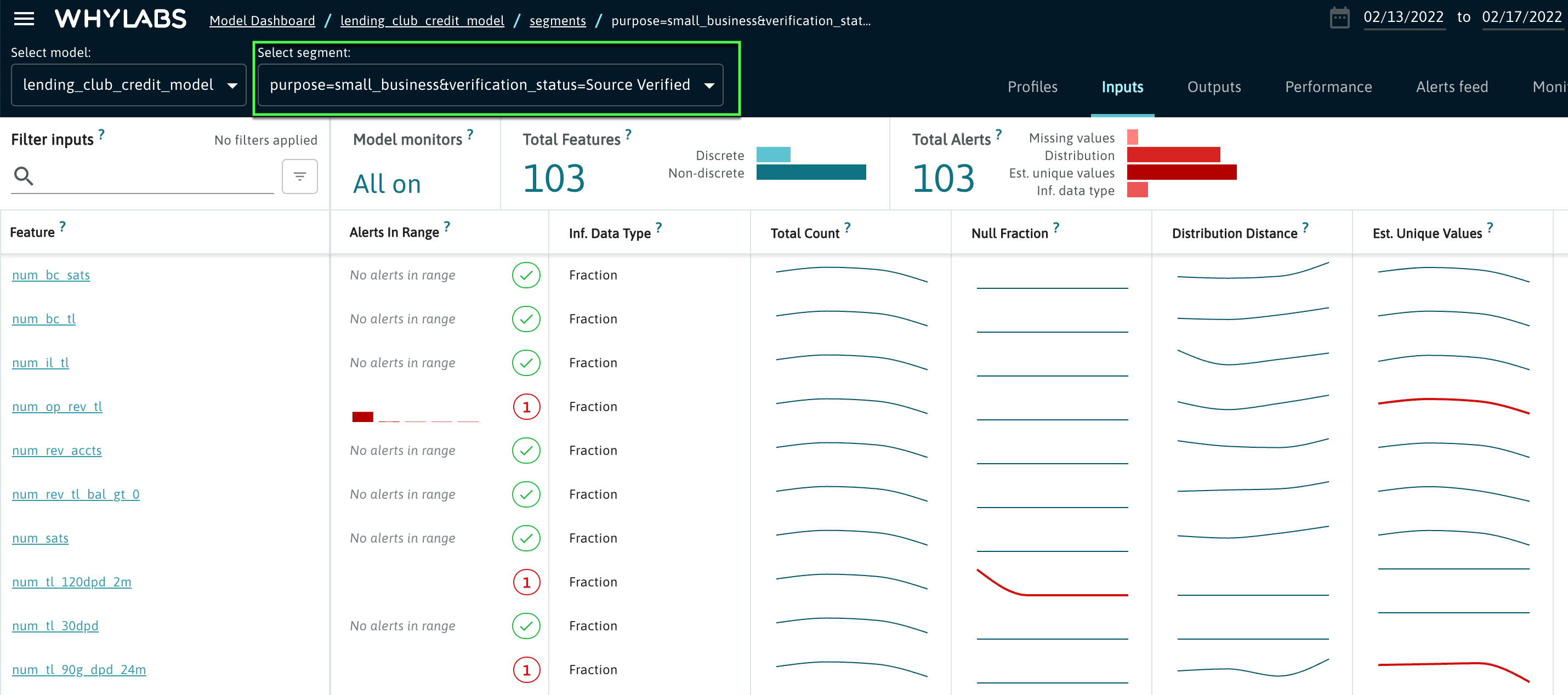
Users can toggle between different segments as desired. Users can also navigate to the profile comparison page, outputs view, and alerts feed for a particular segment.
Note that certain segments may contain alerts even if the overall dataset does not. This can help users to identify anomalous behaviors in these subsets of data even if the impact on the overall dataset was not great enough to warrant an alert.
Segmentation can also help with troubleshooting. When an alert is raised for the overall dataset, users can drill down to the segment level to determine whether particular segments are responsible for the detected anomalies.
Manual Segmentation
There are often domain- and organization-specific factors that determine which features of the data should be treated as segments. For this control, we highly encourage teams set up manual segments on their profiling.
For now, these are done slightly differently in Python and Spark. In Python, you may select segments either at the feature level (i.e., column name) or at the feature-value level (i.e., value for a given column). In the Apache Spark use cases, segments can only be chosen at the feature level at this time.
Python
- whylogs v0
- whylogs v1
# pip install "whylogs<1.0"
from whylogs import get_or_create_session
# Assume a dataset with the following structure:
# index col1 col2 col3
# 0 "a" 1 100
# 1 "b" 2 100
# 2 "c" 1 200
# 3 "a" 2 100
pandas_df = pd.read_csv("demo.csv")
sess = get_or_create_session()
# Option 1: feature level, list of feature names
with sess.logger(dataset_name="my_dataset") as logger:
logger.log_dataframe(pandas_df, segments=["col1", "col3"])
# OR Option 2: feature + value level, nested list of dictionary objects
with sess.logger(dataset_name="my_dataset") as logger:
logger.log_dataframe(pandas_df, segments=[[{"key": "col1", "value": "a"}, {"key": "col3", "value": 100}],
[{"key": "col1", "value": "b"}]
])
import whylogs as why
from whylogs.core.schema import DatasetSchema
from whylogs.core.segmentation_partition import (
ColumnMapperFunction,
SegmentationPartition,
)
# Assume a dataset with the following structure:
# index col1 col2 col3
# 0 "a" 1 100
# 1 "b" 2 100
# 2 "c" 1 200
# 3 "a" 2 100
segmentation_partition = SegmentationPartition(
name="col1,col3", mapper=ColumnMapperFunction(col_names=["col1", "col3"])
)
multi_column_segments = {segmentation_partition.name: segmentation_partition}
results = why.log(df, schema=DatasetSchema(segments=multi_column_segments))
PySpark
- whylogs v0
- whylogs v1
# whylogs v0.x can be installed via the following
# pip install "whylogs<1.0"
import pyspark
whylogs_jar = "/path/to/whylogs/bundle.jar"
spark = pyspark.sql.SparkSession.builder
.appName("whylogs")
.config("spark.pyspark.driver.python", sys.executable)
.config("spark.pyspark.python", sys.executable)
.config("spark.executor.userClassPathFirst", "true")
.config("spark.submit.pyFiles", whylogs_jar)
.config("spark.jars", whylogs_jar)
.getOrCreate()
# This comes from whylogs bundle jar
import whyspark
# Assume a dataset with the following structure:
# index col1 col2 col3
# 0 "a" 1 100
# 1 "b" 2 100
# 2 "c" 1 200
# 3 "a" 2 100
pandas_df = pd.read_csv("demo.csv")
spark_df = spark.createDataFrame(pandas_df)
session = whyspark.WhyProfileSession(spark_df, "my-dataset-name", group_by_columns=["col1", "col3"])
# coming soon!
Scala
// This integration is current in private beta. Please reach out to [email protected] to get access.
import org.apache.spark.sql.functions._
import com.whylogs.spark.WhyLogs._
// Assume a dataset with the following structure:
// index col1 col2 col3
// 0 "a" 1 100
// 1 "b" 2 100
// 2 "c" 1 200
// 3 "a" 2 100
val raw_df = spark.read.csv("demo.csv")
val profiles = df.newProfilingSession("profilingSession")
.groupBy("col1", "col3")
.aggProfiles()
For segmenting at the feature + value level with python, each nested list defines one or more conditions defining each segment. In the example above, there are 2 segments:
Segment 1: “col1” has value “a” and “col3” has value 100
Segment 2: “col1” has value “b”
Note that the aggregated profile for this batch will only contain data belonging to the segments defined above in the case of segmenting at the feature + value level.
Automatic Segmentation
We also provide a simple algorithm for automatic selection of the segmentation features that can be calculated on a static dataset, such as a training dataset. This entropy-based calculation will return a list of features with the highest information gain on which we suggest you segment your data.
This calculation has a number of optional parameters, such as the maximum number of segments allowed.
All methods allow for the segmentation in Python, whylogs will automatically ingest this segment data when profiling data using the same dataset name.
Python
- whylogs v0
- whylogs v1
# whylogs v0.x can be installed via the following
# pip install "whylogs<1.0"
from whylogs import get_or_create_session
pandas_df = pd.read_csv("demo.csv")
sess = get_or_create_session()
auto_segments = sess.estimate_segments(pandas_df, max_segments=10)
with sess.logger(dataset_name="my_dataset") as logger:
logger.log_dataframe(pandas_df, segments=auto_segments)
# coming soon!
PySpark
- whylogs v0
- whylogs v1
# whylogs v0.x can be installed via the following
# pip install "whylogs<1.0"
import pyspark
whylogs_jar = "/path/to/whylogs/bundle.jar"
spark = pyspark.sql.SparkSession.builder
.appName("whylogs")
.config("spark.pyspark.driver.python", sys.executable)
.config("spark.pyspark.python", sys.executable)
.config("spark.executor.userClassPathFirst", "true")
.config("spark.submit.pyFiles", whylogs_jar)
.config("spark.jars", whylogs_jar)
.getOrCreate()
# This comes from whylogs bundle jar
import whyspark
pandas_df = pd.read_csv("demo.csv")
spark_df = spark.createDataFrame(pandas_df)
auto_segments = whyspark.estimate_segments((spark_df, max_segments=10))
session = whyspark.WhyProfileSession(spark_df, "my-dataset-name", group_by_columns=auto_segments)
profile_df = session.aggProfiles().cache()
profile_df.write.parquet('profiles.parquet')
# coming soon!

