BigQuery/Dataflow Integration
If you're using GCP's BigQuery or Dataflow services then you can use our Dataflow template to set up ad-hoc or scheduled profiling jobs. We currently offer the Batch BigQuery Template, that should cover most batch BigQuery use cases. If you have a streaming use case or have some constraint that rules out what's available then reach out on slack and let us know. The current template can be easily modified in various ways.
Batch BigQuery Template
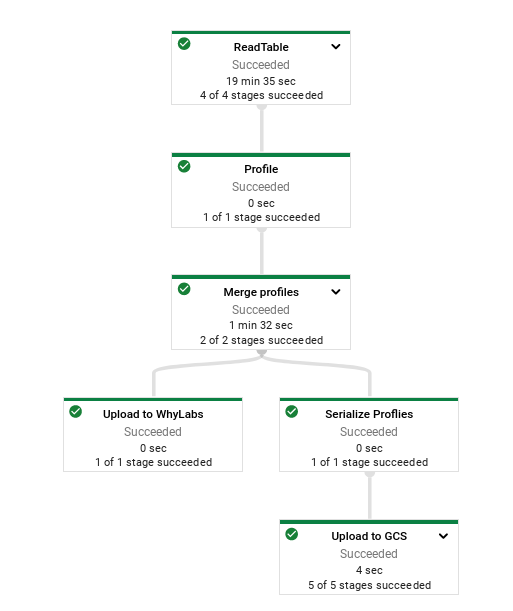
The image above shows what a successful execution of the template will look like. When you execute this template you'll see a step for reading input data (from BigQuery), a step for profiling that data using whylogs, another step for merging the profiles together, and then a fork where one of the branches uploads those profiles to WhyLabs for you, and the other uploads those profiles to GCS.
Location
The template is hosted on a public GCS bucket at gs://whylabs-dataflow-templates/batch_bigquery_template/latest/batch_bigquery_template.json. You can use one of the full sha commits from the github repo's master branch in place of latest for more control over updates.
Configuring: Mandatory Arguments
The template can run in three modes that control how the input is determined.
BIGQUERY_SQL: Use the output of a BigQuery SQL query as the input for the job.
BIGQUERY_TABLE: Use an entire table as the input for a pipeline.
OFFSET: Use a time offset to determine the input for this pipeline. This method is mostly a convenience for easily configuring a pipeline to run on a schedule with static arguments. This mode will use the required options to construct a BigQuery SQL query to target
now - offsetdays. For example, if the configured offset is 1, the offset table isa.b.c, and the date column ismy_timestamp, then this job will execute something like the following query, where the end month/day/year are all computed during the job relative to the job's execution time.SELECT * FROM `a.b.c` WHERE EXTRACT(DAY FROM my_timestamp) = {end.day} AND EXTRACT(YEAR FROM my_timestamp) = {end.year} AND EXTRACT(MONTH FROM my_timestamp) = {end.month}
| Template Argument | Description |
|---|---|
| output | A GCS path to use as the prefix for the generated whylogs profiles. If you use gs://bucket/profile for a job that generates 2 profiles then you'll have 2 files created: gs://bucket/profile_0000-of-0002.bin and gs://bucket/profile_0001-of-0002.bin. |
| input-mode | The mode to run the pipeline in. Different modes change the way the pipeline determines its input, and each one has config that is required if that mode is being used. Can be one of BIGQUERY_SQL, BIGQUERY_TABLE, OFFSET. |
| input-bigquery-sql (if input-mode=BIGQUERY_SQL) | A query to execute against BigQuery. The query should use the fully qualified name of your BigQuery table. For example, SELECT * FROM `myaccount.my-dataset.my-table` WHERE EXTRACT(YEAR FROM my_timestamp) = 2022 AND EXTRACT(MONTH FROM my_timestamp) = 2 AND EXTRACT(DAY FROM my_timestamp) = 10. For a recurring job that you create daily dynamically, you might select the previous day of data from your table. |
| input-bigquery-table (if input-mode=BIGQUERY_TABLE) | A fully qualified BigQuery table of the form PROJECT.DATASET.TABLE. Be careful not to generate too many profiles if you're using this option. By default, we generate a single profile for each day in the dataset so this job might take a long time if you have a wide range of data in your table. It might be helpful to pair this option with a date-grouping-frequency of Y for exploratory analysis, breaking a table into a profile per year, for example. |
| input-offset (if input-mode=OFFSET) | A negative number that represents the amount of days in the past to query for. Set this to -1 if you're targeting the previous day's data. |
| input-offset-table (if input-mode=OFFSET) | The same idea as input-bigquery-table. This should be the fully qualified table to use. |
| date-column | The column in the BigQuery table that contains a TIMESTAMP type. That column will be used by whylogs to group data by time (day by default) and reduce each group into whylogs profiles. There has to be a TIMESTAMP type currently. |
| org-id | The id of your WhyLabs organization. Used for uploading to WhyLabs. |
| dataset-id | The id of your WhyLabs model. Used for uploading to WhyLabs. |
| api-key | An API key for your WhyLabs account. You can generate this in the Settings menu in WhyLabs. |
Configuring: Optional Arguments
| Template Argument | Description |
|---|---|
| segment-columns | Optionally segment data on specified columns. These columns will be used by whylogs to split the data into groups and create partial profiles for each subset. Segmenting on a categorical column with three unique values will result in three profiles being generated, segmenting on two columns that each have three unique values will result in six profiles being generated, etc. Take care when picking columns for segmentation and refer to the docs on segmentation. |
| input-offset-timezone (if input-mode=OFFSET) | If the pipeline is running in OFFSET mode then the timezone can be optionally configured. It's used in date math when calculating the start/end time of the query. It defaults to UTC. |
| logging-level | A python logging level to use. Defaults to INFO. |
| date-grouping-frequency | A pandas Grouper frequency to use. This determines how the data is grouped by time before turning it into whylogs profiles. Defaults to D (for "daily"). See the pandas docs for options. |
Running: From the GCloud Console as a template, once
Running the template manually from the console UI can be a convenient way to test it out before productionalizing it on a schedule. It's also convenient for seeing all of the template's arguments displayed as text fields with real time input validation.
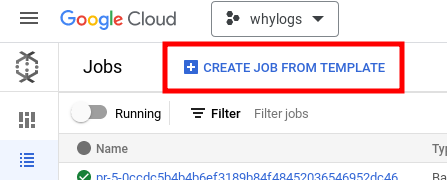
- Go to the Dataflow home page in the GCP console and pick "CREATE JOB FROM TEMPLATE".
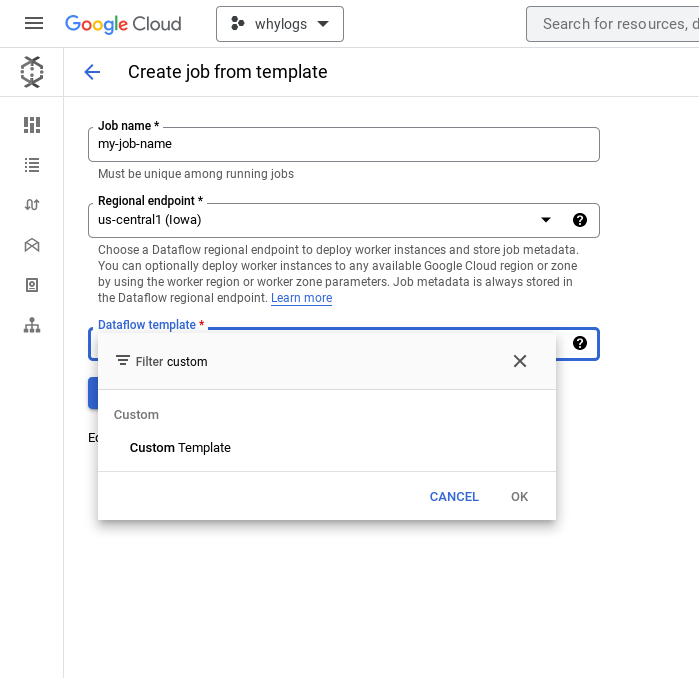
- Enter a job name and use the Dataflow template search box to select "Custom Template"
- Enter the path to the template from the Location section above. The UI should auto expand to populate the arguments for the template.
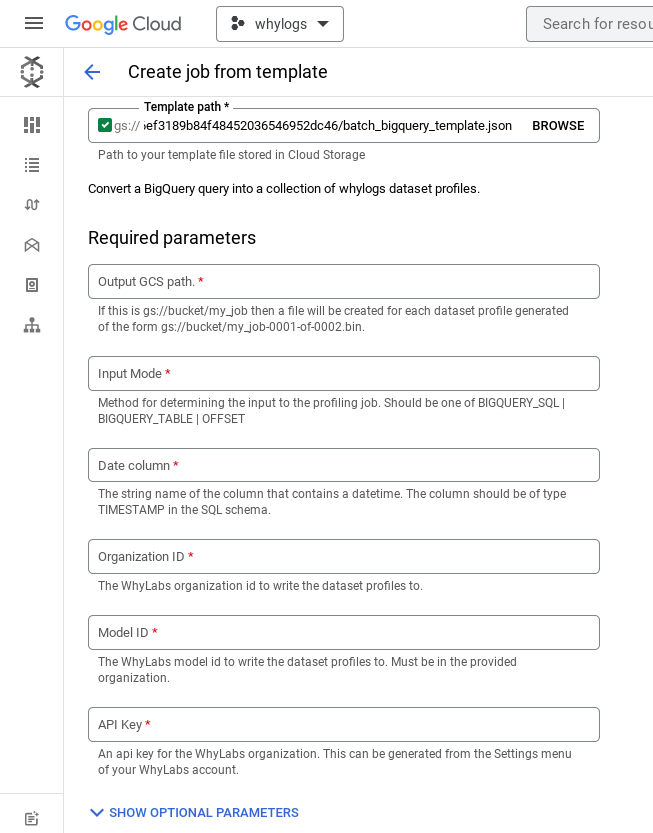
- Follow Configuring: mandatory arguments to populate all of the template arguments. You'll have to expand the optional parameter section as well since some of the arguments are required depending on what you pick in the required section.
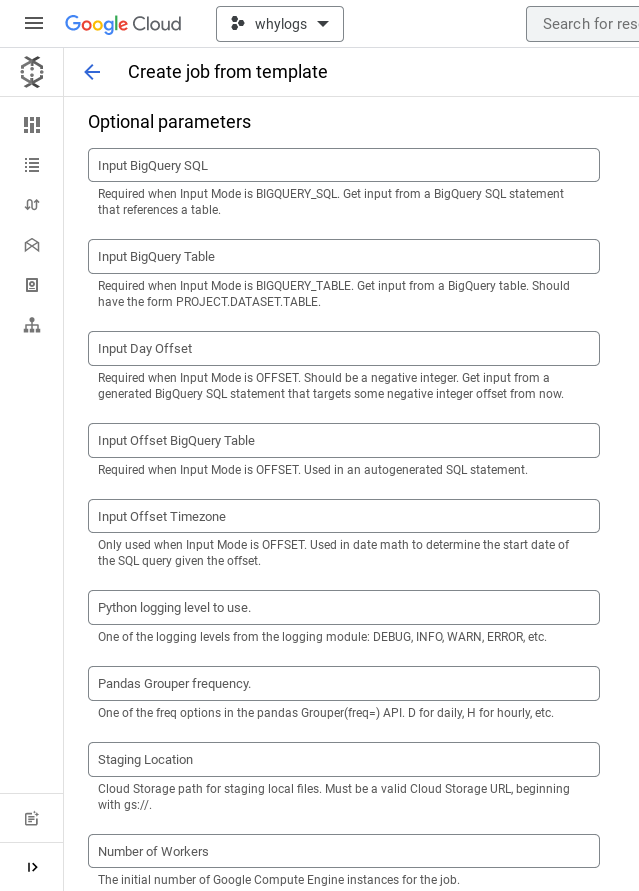
Running: From the GCloud Console as a template, scheduled
You can run the template as a Dataflow Pipeline as well. If you already have a completed batch job you can convert that into a recurring pipeline with the IMPORT AS PIPELINE button.
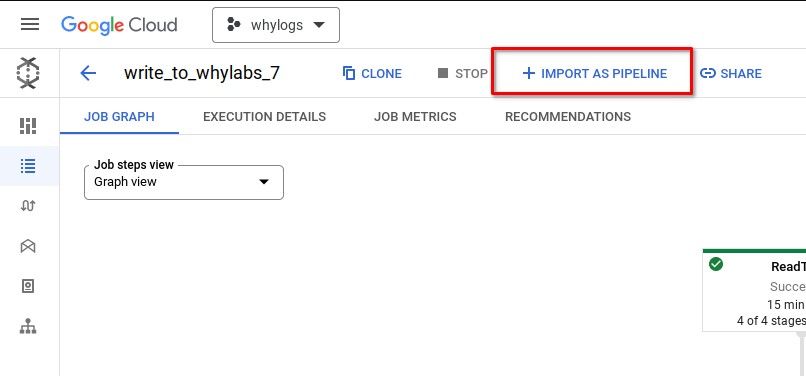
You'll see the same form as though you were running the template directly. The only thing to note is that you'll have to run the pipeline in batch mode instead of streaming mode since the template makes some assumptions about the input data that aren't compatible with streaming right now. Reach out to us on slack if you're interested in having a streaming version of this template.
Running: From CLI as a template
The easiest way to run from the CLI is with the gcloud command. Instead of filling in text fields in the console you'll manually specify the parameters. The validation from the UI still works as well. Here is an example of running the template in BIGQUERY_TABLE mode against a hacker news public dataset. The dataset spans 10 years and the date-grouping-frequency is set to Y, so this job will generate 10 whylogs profiles in GCS with names like gs://whylabs-dataflow-templates-tests/my-job-name/dataset_profile-0001-of-0010. At the end of the job, the profiles will be uploaded to WhyLabs under org-0's model-42.
gcloud dataflow flex-template run "my-job-name" \
--template-file-gcs-location gs://whylabs-dataflow-templates/batch_bigquery_template/latest/batch_bigquery_template.json \
--parameters input-mode=BIGQUERY_TABLE \
--parameters input-bigquery-table=bigquery-public-data.hacker_news.comments \
--parameters date-column=time_ts \
--parameters date-grouping-frequency=Y \
--parameters org-id=org-0 \
--parameters dataset-id=model-42 \
--parameters output=gs://whylabs-dataflow-templates-tests/my-job-name/dataset_profile \
--parameters api-key=my-api-key \
--region us-central1
Running: From CLI as a pipeline
You can also run the pipeline directly without using it as a template. You can do this if you want to test some alternate pipeline configuration by editing and running our template. The easiest way to do this is by checking out our template repo and using our Makefile.
git checkout https://github.com/whylabs/dataflow-templates.git
cd dataflow-templates
poetry install # need to download and install poetry first
make example_run_direct_table NAME=test
Many of the variables in there are hard coded to developer values for CI, but you'll be able to see the command it would execute to run the pipeline right away.

