whylogs Container
⚠️ This page refers to the newer Python based container. For the Java based container docs, see these docs
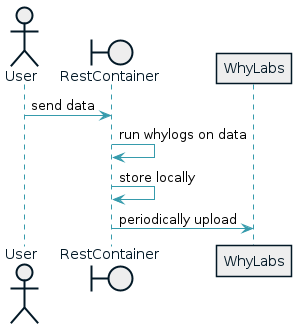
The whylogs container is a good integration solution for anyone that doesn't want to manually include the whylogs library into their data pipeline. Rather than adding whylogs code to an existing application, you'll send post requests with data to this container and that data will be converted into whylogs profiles and occasionally uploaded to WhyLabs.
You can more or less think of the container as a dictionary of timestamps to whylogs profiles. As data is uploaded, the timestamp of that data is used to reduce it into the existing profile for that timestamp if one exists, otherwise one is created. Periodically, all of the profiles that are stored in the container are uploaded one-by-one based on the container's configuration and local copies are erased.
Configuration
There are two types of config. Simple config that can be passed via env variables and custom config that is specified as python source and built into the container.
Env Configuration
If you only need basic data profiling then you can use the container directly from Docker with only env configuration. Below is a sample. You can find the full list of env variables here.
##
## REQUIRED CONFIG
##
# An api key from the org
WHYLABS_API_KEY=xxxxxxxxxx.xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx:org-xx
# One of these two must be set
# Sets the container password to `password`. See the auth section for details
CONTAINER_PASSWORD=password
# If you don't care about password protecting the container then you can set this to True.
DISABLE_CONTAINER_PASSWORD=True
##
## OPTIONAL CONFIG
##
# Safeguard if you're using custom configuration to guarantee the container is correctly built to use it.
FAIL_STARTUP_WITHOUT_CONFIG=True
# The default dataset type to use between HOURLY and DAILY. This determines how data is grouped up into
# profiles before being uploaded. You need to make sure this matches what you configured the dataset as
# in your WhyLabs settings page.
DEFAULT_WHYLABS_DATASET_CADENCE=HOURLY | DAILY
# The frequency that uploads occur, being denoted in either minutes (M), hours (H), or days (D).
DEFAULT_WHYLABS_UPLOAD_CADENCE=M | H | D
# The interval, given the configured cadence. Setting this to 15 with a cadence of M would result in uploads every 15 minutes.
DEFAULT_WHYLABS_UPLOAD_INTERVAL=15
Custom configuration
There are some use cases that env variables can't be used for, like defining a dataset schema with a custom Python function that checks constraints. For complex use cases, you can define a whylogs dataset schema in Python and build your own container. We have an example repo that demonstrates this here.
Running
If you want to run the container without any custom whylogs configuration then you don't have to worry about the Dockerfile or python code. You can just start the container with docker and pass your env variables.
docker run -it --rm -p 127.0.0.1:8000:8000 --env-file local.env registry.gitlab.com/whylabs/whylogs-container:latest
If you want to use custom whylogs configuration then you'll need to build the container yourself using a simple Dockerfile like the one from our example repo.
docker build . -t my-whylogs-container
docker run -it -p 127.0.0.1:8000:8000 --env-file local.env my-whylogs-container
Usage
The REST API of the container can be viewed as a swagger page on the container itself, hosted at http:<container>:<port>/docs. You can also view the API docs from the most recent build here.
The container can be called with our generated python client. The data format of the
REST interface was made with pandas in mind. The easiest way to get the data for the log api if you're using pandas is as follows.
import time
import pandas as pd
import whylogs_container_client.api.profile.log as Log
from whylogs_container_client.models.log_multiple import LogMultiple
df = pd.DataFrame({"a": [1, 2], "b": [2.1, 33.3], "c": ["foo", "bar"]})
now_ms_epoch = int(time.time() * 1000)
request = LogRequest(
dataset_id="model-1",
timestamp=now_ms_epoch,
multiple=LogMultiple.from_dict(df.to_dict(orient="split")), # pyright: ignore[reportUnknownArgumentType,reportUnknownMemberType]
)
Log.sync_detailed(client=client_external, body=request)
Or, without pandas
import time
import whylogs_container_client.api.profile.log as Log
from whylogs_container_client.models.log_multiple import LogMultiple
now_ms_epoch = int(time.time() * 1000)
request = LogRequest(
dataset_id="model-1",
timestamp=now_ms_epoch,
# without pandas
multiple=LogMultiple(columns=["a", "b", "c"], data=[[1, 2.1, "foo"], [2, 33.3, "bar"]]),
)
Log.sync_detailed(client=client, body=request)
If you're just trying to test the container, you can use the following curl command and sample request to send data to the container.
curl -X 'POST' \
-H "X-API-Key: <password>" \
-H "Content-Type: application/json" \
'http://localhost:8000/log' \
--data-raw '{
"datasetId": "model-62",
"multiple": {
"columns": [ "age", "workclass", "fnlwgt", "education" ],
"data": [
[ 25, "Private", 226802, "11th" ]
]
}
}'
Performance and Infrastructure
Here are some benchmarks to help you decide what hardware to host the container on and how many instances to spin up. Some additional parameters for each of these tests:
- 5 minute load testing using the
/logendpoint. - Single m5.large AWS host for the container
- Separate m5.large AWS host sending requests from the same region with 4 concurrent clients
- Various request sizes where a row is a data point and a feature is a column.
| Features | Rows | Requests per second | Rows per second | Additional Config | p99 request time (ms) |
|---|---|---|---|---|---|
| 20 | 1 | 2,257 | 2,257 | 1.8 | |
| 20 | 10 | 1,831 | 18,310 | 2.7 | |
| 20 | 100 | 232 | 23,200 | MAX_REQUEST_BATCH_SIZE=5000 | 4.2 |
| 20 | 1000 | 23 | 23,000 | MAX_REQUEST_BATCH_SIZE=500 | 14 |
| 150 | 1 | 1,752 | 1,752 | 2.8 | |
| 150 | 10 | 528 | 5,280 | 3.3 | |
| 150 | 100 | 69 | 6,900 | MAX_REQUEST_BATCH_SIZE=1000 | 5.6 |
| 150 | 1000 | 7 | 7,000 | MAX_REQUEST_BATCH_SIZE=250 | 80 |
Some recommendations:
- Pick a host with at least 4GB of memory.
- If you're sending a lot of data then you may need to tune some env variables for performance, like is done above. If you're way under the requests per second in the table then you shouldn't need to tune anything.
The performance depends on how many rows and features you send in each request. If you have 20 features and you only send a single data point in each request then you can expect around 2,000 sustained requests per second with one instance of the container running on an m5.large host.
There are two performance parameters you can tune: MAX_REQUEST_BATCH_SIZE and MAX_REQUEST_BUFFER_BYTES. The container queues all incoming requests and sends them to a dedicated python process that does the whylogs profiling. If you're sending requests with a lot of rows (100 or more) then you might need to reduce the MAX_REQUEST_BATCH_SIZE env variable because processing happens on the message level, which can end up ooming the container if it tries to process 50,000 requests with 100 rows each at once. That's why the load tests above include the performance tuning that was included to ensure stability (if any was needed). It's unlikely that you'll have to touch MAX_REQUEST_BUFFER_BYTES. The default of 1GB should be enough to smooth out performance during traffic spikes by allowing the container to queue the messages internally and get to them as soon as it can. That entire process is async and the requestors only end up waiting if the internal queue is full.
The container is stateful. You shouldn't spin up short lived instances to handle a small number of requests. The container depends on accumulating data over time and periodically uploading the profiles.
While you can add additional instances as you need to meet demand, you shouldn't add far more than you need. Each container instance independently accumulates data into profiles. That means that each instances will have a subset of the data for your data set, which is normally completely fine. If you have 5 instances then you'll end up generating 5 profiles each hour (for an hourly data set) and we'll merge them together for you after upload. If you have 100 instances and they each only end up getting a few datapoints per hour then the accuracy of some of the metrics inside of our profiles can be affected.
FAQ
Is the Java container still supported?
Yes, but the Java container won't ever be parity with the Python container in terms of whylogs features. We made the Python version so that we could directly use the Python version of whylogs, which is ahead of our Java whylogs library in terms of features because various dependencies are only available in Python (ML model frameworks, Pandas, etc). For basic data profiling, the Java container slightly out performs the Python container and it has some integration options (like Kafka) that don't exist in the Python version yet. But the Python container will always have more whylog features.
Troubleshooting
If you need help setting up the container then reach out to us on Slack. You can also contact us via email to submit issues and feature requests for the container.

