Kafka container
⚠️ This page refers to the Java-based container for Kafka. For the new Python based container docs, see these docs
The whylogs container is a good integration solution for anyone that doesn't want to manually include the whylogs library into their data pipeline. Rather than adding whylogs code to an existing application, you'll send post requests with data to this container and that data will be converted into whylogs profiles and occasionally uploaded to WhyLabs or S3. You can host the container on whichever container platform you prefer and it can be configured to run in several different modes that are covered below.
You can more or less think of the container as a dictionary of timestamps to whylogs profiles. As data is uploaded, the timestamp of that data is used to reduce it into the existing profile for that timestamp if one exists, otherwise one is created. Periodically, all of the profiles that are stored in the container are uploaded one-by-one based on the container's configuration and local copies are erased.
Like whylogs, the container is open source and we welcome contributions and feedback.
Configuration
The container is configured through environment variables. See the environment variable documentation for a list of all of the variables, their meanings, and their default values.
When you configure the container you're primarily picking two things: a method for getting data into the container to be converted into profiles, and a destination for those profiles to be uploaded to. These options are independent, so you can pair whichever input method you prefer with any upload method.
For ingesting data, the container has a REST interface and a Kafka consumer based interface. For uploading profiles, the container can target WhyLabs, S3, or local file system.
REST Interface
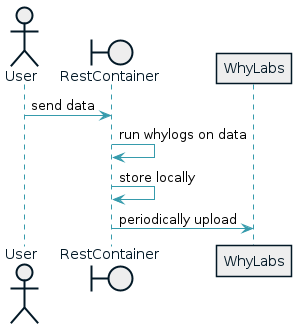
The default data ingestion method is the REST interface. Below is a minimal configuration to take data from REST calls and upload them to WhyLabs.
## WhyLabs specific configuration
# The data type of your WhyLabs project
WHYLOGS_PERIOD=DAYS
# Created from the Settings menu in your WhyLabs account
WHYLABS_API_KEY=xxxxxxxxxx.xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
# Your WhyLabs org id
ORG_ID=org-1234
## General container configuration
# A string that the container checks for in the X-API-Key header during each request
CONTAINER_API_KEY=password
PORT=8080
The REST API of the container can be viewed as a swagger page on the container itself, hosted at http:<container>:<port>/swagger-ui. You can also view the API docs from the most recent build here.
The data format of the REST interface was made with pandas in mind. The easiest way to get the data for the log api if you're using pandas is as follows.
import pandas as pd
cars = {'Brand': ['Honda Civic','Toyota Corolla','Ford Focus','Audi A4'],
'Price': [22000,25000,27000,35000] }
df = pd.DataFrame(cars, columns = ['Brand', 'Price'])
df.to_json(orient="split") # this is the value of `multiple`
Kafka Interface
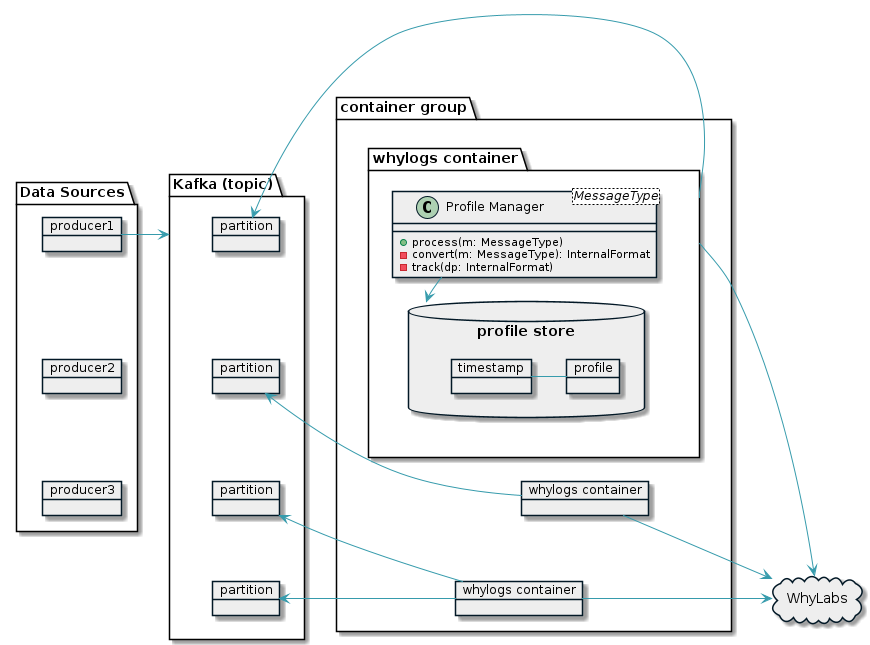
The container can also run as a Kafka consumer. The configuration below will consume data from a Kafka cluster located at http://localhost:9092, from the topic my-topic (which we'll say has been configured to have 4 partitions), using 4 Kafka consumers with dedicated threads, uploading profiles to WhyLabs for org-1235's model-2156.
# Include all of the WhyLabs configuration if you're sending profiles to WhyLabs still
WHYLOGS_PERIOD=DAYS
WHYLABS_API_KEY=xxxxxxxxxx.xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
ORG_ID=org-1234
CONTAINER_API_KEY=password
PORT=8080
## Kafka configuration
KAFKA_ENABLED=true
# Required if you're sending profiles to WhyLabs
KAFKA_TOPIC_DATASET_IDS={"my-topic": "model-2156"}
KAFKA_BOOTSTRAP_SERVERS=["http://localhost:9092"]
KAFKA_GROUP_ID=my-group-id
KAFKA_TOPICS=["my-topic"]
# Threads can match your topic partition count
KAFKA_CONSUMER_THREADS=4
The REST interface is still active when Kafka is enabled. The KAFKA_CONSUMER_THREADS option controls how many consumer instances are started. Each one of them is given a dedicated thread to run on, so one container can have multiple consumers at once. The thread count should probably be set to the partition count of your Kafka topic, feel free to reach out for advice while you're configuring though.
The container assumes JSON format for the data in the topic. Nested values will be flattened into keys like a.b.c by default, but can be configured via a environment variable.
WhyLabs Publishing
The REST configuration above also highlighted sending profiles to WhyLabs.
## WhyLabs specific configuration
# The data type of your WhyLabs project
WHYLOGS_PERIOD=DAYS
# Created from the Settings menu in your WhyLabs account
WHYLABS_API_KEY=xxxxxxxxxx.xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
# Your WhyLabs org id
ORG_ID=org-1234
## General container configuration
# A string that the container checks for in the X-API-Key header during each request
CONTAINER_API_KEY=password
PORT=8080
This will result in daily uploads of daily data to your WhyLabs account. You can get an access token from the token management page in your account settings.
S3 Publishing
Below is a minimal configuration for uploading profiles to s3.
UPLOAD_DESTINATION=S3
S3_PREFIX=my-prefix
S3_BUCKET=my-bucket
WHYLOGS_PERIOD=DAYS
# Uses the AWS Java SDK for auth via environment variables
AWS_ACCESS_KEY_ID=xxxxxxxxxxxxxxxxxxxx
AWS_SECRET_ACCESS_KEY=xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
AWS_REGION=us-west-2
CONTAINER_API_KEY=password
PORT=8080
The container uses the AWS Java SDK so authentication happens through the standard environment variables that it checks. Once configured, profiles are uploaded to the specified bucket in the following format.
# Unique id generated for each profile
s3://container-test-bucket-123/my-prefix/2022-09-01/Mw6E34_2022-09-01T00:00:00.bin
Local Publishing
Below is a minimal configuration for writing files to disk.
UPLOAD_DESTINATION=DEBUG_FILE_SYSTEM
FILE_SYSTEM_WRITER_ROOT=my-profiles
WHYLOGS_PERIOD=DAYS
CONTAINER_API_KEY=password
PORT=8080
This was developed as a debugging tool mostly but could come in handy if external storage was mounted to the right location in the container. The profiles are written to disk in the following format.
# Unique id generated for each profile
/opt/whylogs/my-profiles/2022-09-01/R866vu_2022-09-01T00:00:00Z.bin
Let us know if you have a use case around this and we'll work to smooth out some of the rough edges.
Performance and Infrastructure
Here are some benchmarks to help you decide what hardware to host the container on and how many instances to spin up. Some additional parameters for each of these tests:
- 5 minute load testing
- Single m5.large AWS host for the container
- Separate m5.large AWS host sending requests from the same region with 4 concurrent clients
| Features | Rows | Requests per second | Rows per second |
|---|---|---|---|
| 20 | 1 | 4,600 | 4,600 |
| 20 | 10 | 2,700 | 27,000 |
| 20 | 100 | 570 | 57,000 |
| 20 | 1000 | 60 | 60,000 |
| 150 | 1 | 2,600 | 2,600 |
| 150 | 10 | 800 | 8,000 |
| 150 | 100 | 87 | 8,700 |
| 150 | 1000 | 8 | 8,000 |
The performance depends on how many rows and features you send in each request. If you have 20 features and you only send a single data point in each request then you can expect around 4,600 sustained requests per second with one instance of the container running on an m5.large host, etc. There is a fair bit of efficiency you gain from sending more data per request, but you can always add additional instances if you need them.
The container is stateful. You shouldn't spin up short lived instances to handle a small number of requests. The container depends on accumulating data over time and periodically uploading the profiles.
While you can add additional instances as you need to meet demand, you shouldn't add far more than you need. Each container instance independently accumulates data into profiles. That means that each instances will have a subset of the data for your data set, which is normally completely fine. If you have 5 instances then you'll end up generating 5 profiles each hour (for an hourly data set) and we'll merge them together for you after upload. If you have 100 instances and they each only end up getting a few datapoints per hour then the accuracy of some of the metrics inside of our profiles will be affected.
Troubleshooting
If you need help setting up the container then reach out to us on Slack or via email. See the Github repo for submitting issues and feature requests.

