Streaming Logging
ML models are often trained using fixed datasets over a given time interval. In production, however, data flows into the model in real-time, unbounded by business hours or other natural boundaries.
There are at least two challenges to monitoring continuous streams of data. The first is segmenting
the stream so intermediate results can be made available. The second is scaling the monitoring solution
to match the rate at which data is consumed with the rate at which
data enters the stream. Monitoring with whylogs can easily meet both these challenges, and
still provide complete statistical profile of the
entire stream.
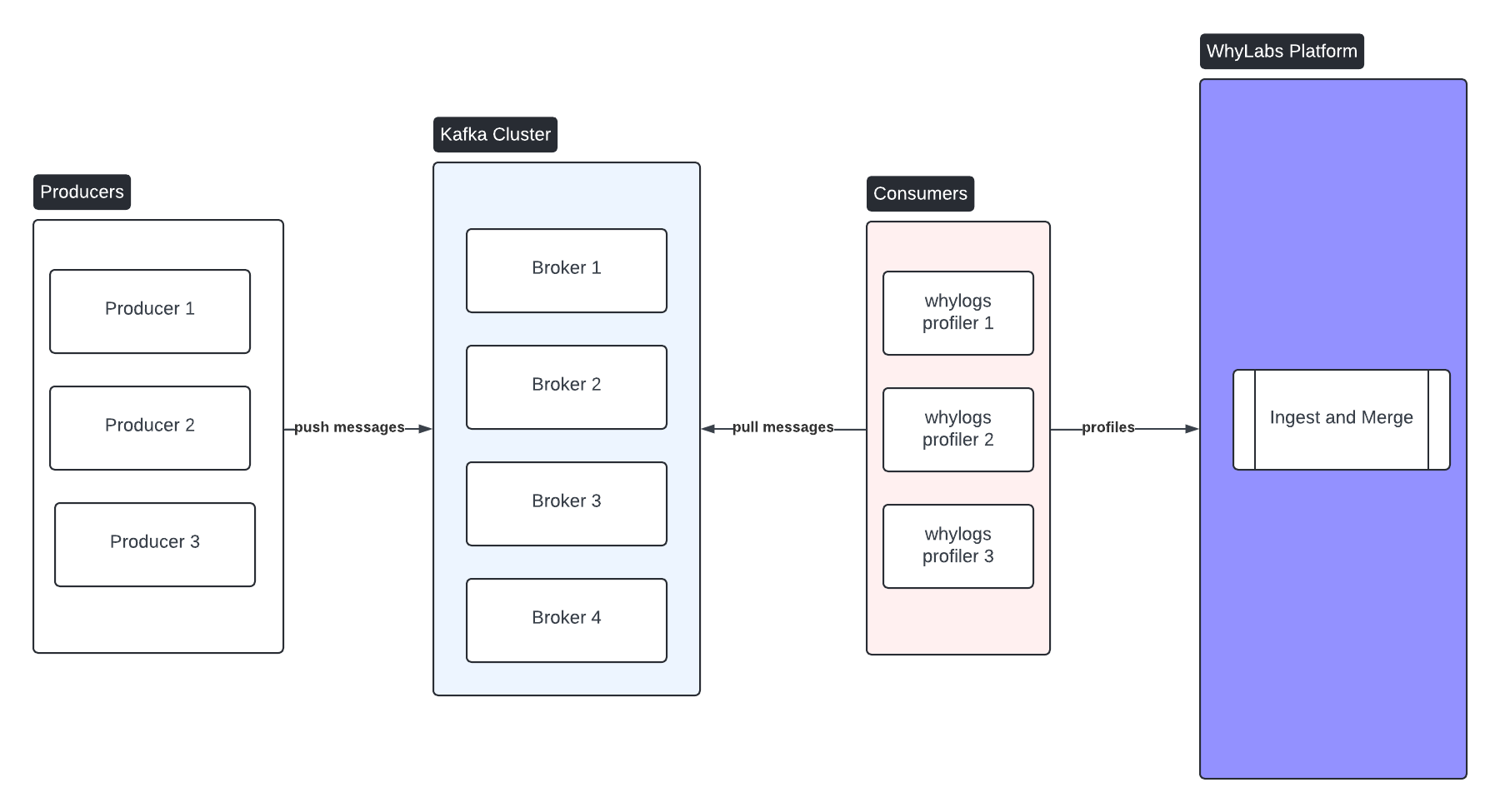
Let's start by talking about dividing a stream into batches so we can view intermediate results. In our examples we'll imagine an abstract stream that pulls new records with each api call. The stream might be supplied by from a Kafka topic or from the endpoint of a messaging queue like SNS or SQS. It is not difficult to extend this solution to fetch multiple records from the stream at once.
We start by creating a session object. A session object can coordinate the activity of multiple loggers and upload data to whylabs.ai if using the whylabs dashboard. From the session, we can create a logger for a specific dataset timestamp. The timestamp often represents a window of data or a batch of data.
- whylogs v0
- whylogs v1
# whylogs v0.x can be installed via the following
# pip install "whylogs<1.0"
from whylogs import get_or_create_session
session = get_or_create_session()
with session.logger(dataset_name="dataset", with_rotation_time="10M") as logger:
for record in stream.get_data():
logger.log(record)
import whylogs as why
with why.logger(mode="rolling", interval=5, when="M", base_name="test_base_name") as logger:
logger.append_writer("local", base_dir="whylogs_output")
for record in stream.get_data():
logger.log(record)
As data is read from the stream it is fed into the logger for processing. If the stream were of limited duration, your logging loop might look like the next example. the whylogs profile is written to disk when the session is closed.
Batching Streams
Streams often do not have clear boundaries when it makes sense to complete one logging profile and begin the next.
Logger objects can optionally batch profiles by time interval automatically,
- whylogs v0
- whylogs v1
# whylogs v0.x can be installed via the following
# pip install "whylogs<1.0"
session = get_or_create_session()
with session.logger(dataset_name="dataset", with_rotation_time="10m") as logger:
for record in stream.get_data():
logger.log(record)
with why.logger(mode="rolling", interval=10, when="M", base_name="test_base_name") as logger:
logger.append_writer("local", base_dir="whylogs_output")
for record in stream.get_data():
logger.log(row=record)
In this example, the logger generates a new profile according to the specified time interval, in this case every 10 minutes.
The interval may be specified in units of seconds ("S"), minutes ("M"), hours ("H"), or days ("D") with an optional multiplier.
When using log rotation, profiles will be written to disk using names suffixed with a timestamp, e.g. "dataset_profile.2021-03-26_16-23-11.bin" The exact format of the date suffix will depend on the granularity of the rotation interval.
In order to write profiles to WhyLabs instead of to local disk, users should append the WhyLabs writer instead of the local writer as shown below. See the Onboarding to the Platform page for more on using the WhyLabs writer.
logger.append_writer("whylabs")

