Language Models
Motivation
The adoption of proprietary, foundational large language models (LLMs) presents unique observability challenges. While fine-tuning and retraining offer benefits, models may deviate from initial versions. Users often have limited access to the vast original training data, resulting in reduced accuracy, unpredictable behavior, hallucinations, and poor understanding of the model's inherent characteristics.
Organizations using LLMs to:
- Validate and safeguard individual prompts & responses
- Evaluate that the LLM behavior is compliant with policy
- Monitor user interactions inside an LLM-powered application
- Compare and A/B test across different LLM and prompt versions
Getting started with LangKit
LangKit is an open-source tool built on whylogs that provides AI practitioners the ability to extract critical telemetry from prompts and responses, which can be used to help direct the behavior of an LLM through better prompt engineering and systematically observe at scale.
The currently supported metrics include:
- Text Quality
- readability score
- complexity and grade scores
- Text Relevance
- Similarity scores between prompt/responses
- Similarity scores against user-defined themes
- Security and Privacy
- patterns - count of strings matching a user-defined regex pattern group
- jailbreaks - similarity scores with respect to known jailbreak attempts
- prompt injection - similarity scores with respect to known prompt injection attacks
- refusals - similarity scores with respect to known LLM refusal of service responses
- Sentiment and Toxicity
- sentiment analysis
- toxicity analysis
Running with LangKit is as easy as a few lines of code which will apply a number of metrics by default:
from langkit import llm_metrics
import whylogs as why
why.init(session_type='whylabs_anonymous')
results = why.log({"prompt":"hello!", "response":"world!"}, name="openai_gpt4", schema=llm_metrics.init())
Extending LangKit using user defined functions (UDFs)
LangKit is incredibly extensivle through User Defined Functions (UDFs). Define a method and decorate it to extract your own metric or validate your prompts and responses with your organizations internal metrics.
@register_metric_udf(col_name='prompt')
def contains_classification_instructions(text):
lower_text = text.lower()
for target in ['classify','identify','categorize']:
if target in lower_text:
return 1
return 0
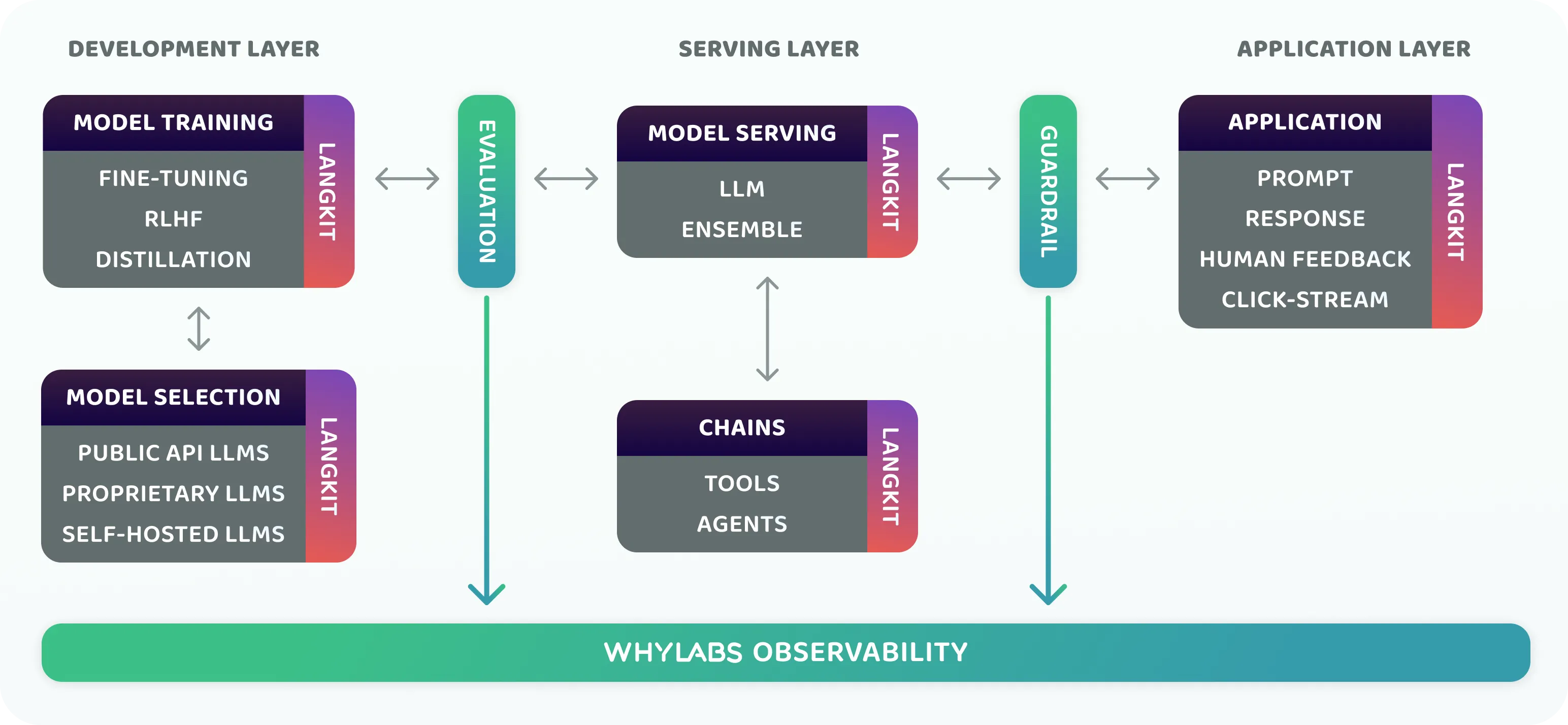
Integrating into LLM pipelines
LangKit is lightweight and fast enough to be integrated into various stages of your LLM pipelines -- such as at model training, model selection, or model serving time. This enables a variety of critical analyses.
Monitor with WhyLabs
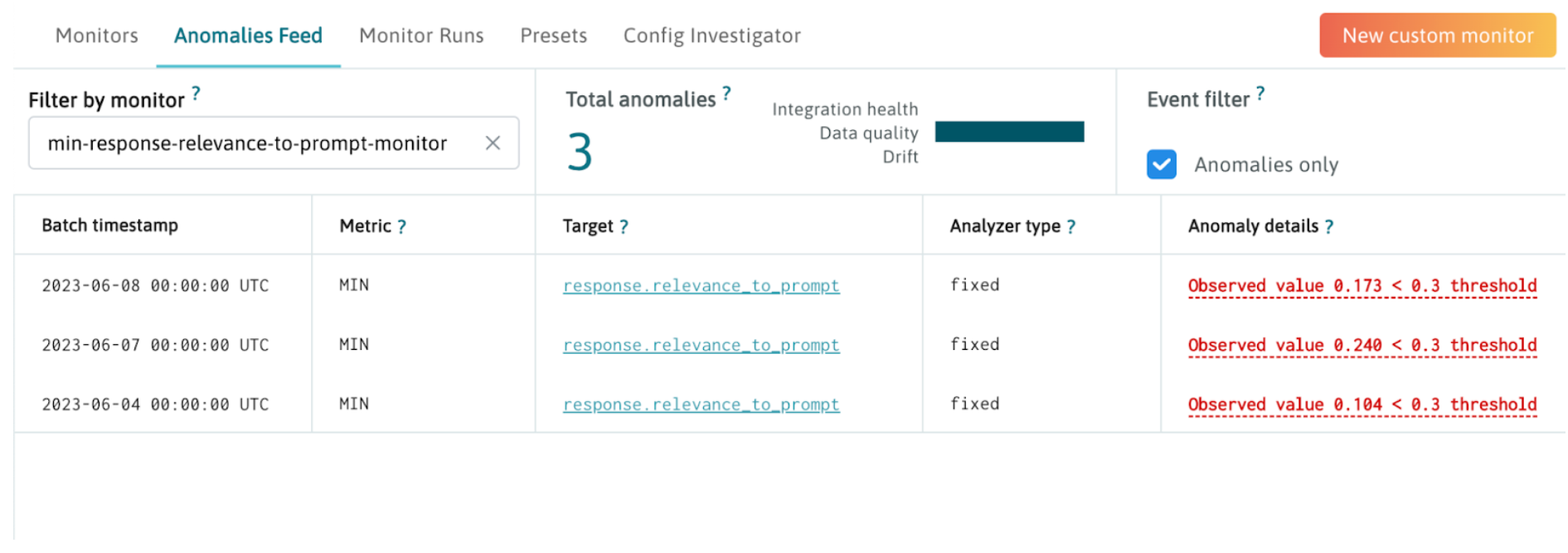
With WhyLabs, users can establish thresholds and baselines for a range of activities, such as malicious prompts, sensitive data leakage, toxicity, problematic topics, hallucinations, and jailbreak attempts. These alerts and guardrails enable any application developer to prevent inappropriate prompts, unwanted LLM responses, and violations of LLM usage policies without having to be an expert in natural language processing.
For example, you may monitor for drift between topics discovered for each prompt and response.