Overview
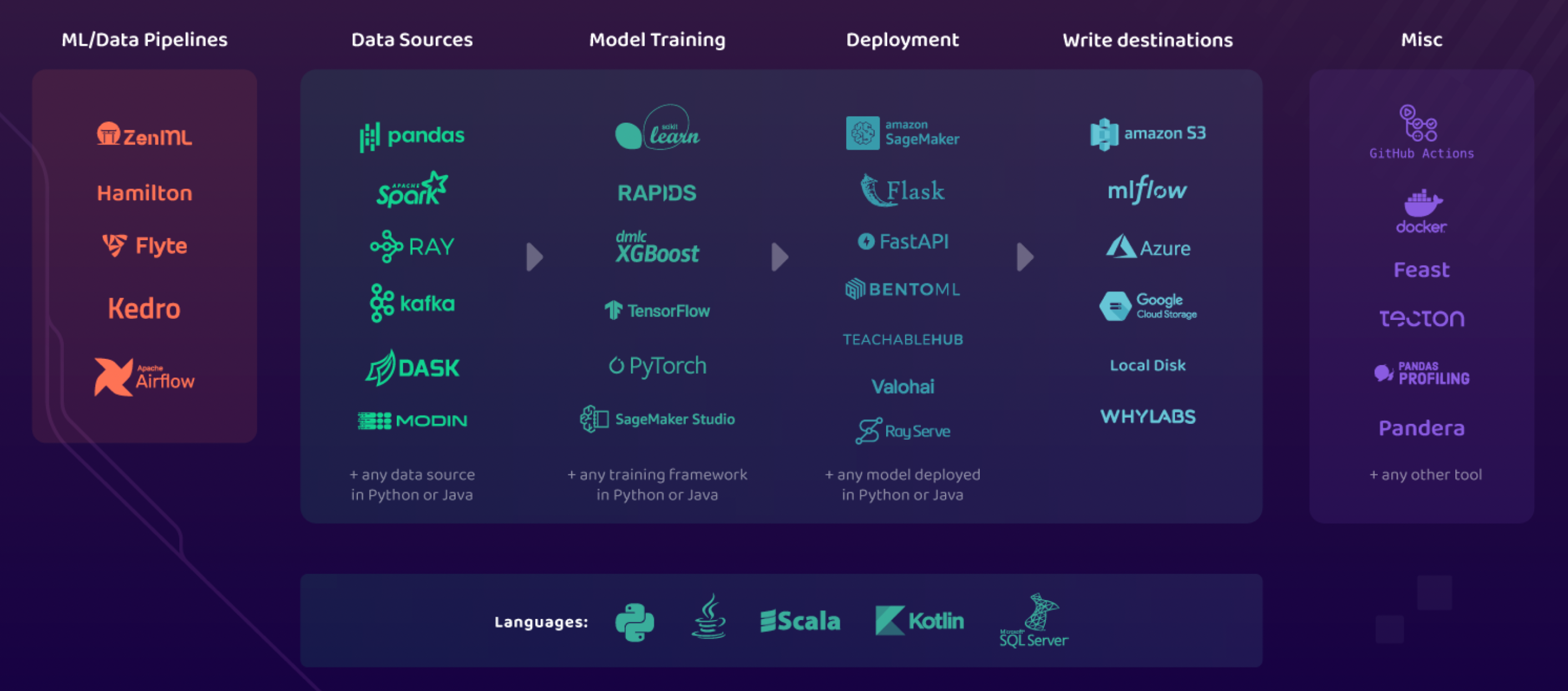
AI Observatory is the Glue of the MLOps Ecosystem
AI Observatory is built on the idea that the strength of a monitoring tool is in its ability to bring together information from many sources and to send actionable insights to many workflows. With this idea, there are many types of integrations that are supported:
- WhyLabs integration with the WhyLabs Observability Platform for ad-hoc debugging, monitoring, and notification workflows
- Data pipelines integrations with various data and ml pipelines such as Spark, Ray, Kafka, etc.
- Model frameworks integrations with frameworks such as scikit-learn, tensorflow, PyTorch, etc.
- Model lifecycle integrations with model lifecycle tools such as MLflow, Airflow, Flyte, etc.
- Notification integrations with common team workflows, such as Slack, PagerDuty, ServiceNow, etc.
Our complete list of integrations can be found on the following sections:
WhyLabs
You can monitor your whylogs profiles continuously with the WhyLabs Observability Platform. The platform is built to work with whylogs profiles and it enables observability into data projects and ML models, with easy-to-set-up workflows that can be triggered when anomalies are detected.
| Integration | Description |
|---|---|
| Writing profiles | Send profiles to your WhyLabs Dashboard |
| Reference Profile | Send profiles as Reference (Static) Profiles to WhyLabs |
| Regression Metrics | Monitor Regression Model Performance Metrics with whylogs and WhyLabs |
| Classification Metrics | Monitor Classification Model Performance Metrics with whylogs and WhyLabs |
For more information on the WhyLabs Observability Platform start here.
Data Pipelines
| Integration | Description |
|---|---|
| Apache Spark | Profile data in an Apache Spark environment |
| BigQuery | Profile data queried from a Google BigQuery table |
| Dask | Profile data in parallel with Dask |
| Databricks | Learn how to configure and run whylogs on a Databricks cluster |
| Fugue | Use Fugue to unify parallel whylogs profiling tasks |
| Kafka | Learn how to create a Kafka integration to profile streaming data from an existing Kafka topic, or attach a container to a topic to automatically generate profiles. |
| Ray | Profile Big Data in parallel with the Ray integration |
Storage
| Integration | Description |
|---|---|
| s3 | See how to write your whylogs profiles to AWS S3 object storage |
| GCS | See how to write your whylogs profiles to the Google Cloud Storage |
| BigQuery | Setup automatic jobs to profile data from BigQuery tables using our no-code templates. |
Model lifecycle and deployment
| Integration | Description |
|---|---|
| Apache Airflow | Use Airflow Operators to create drift reports and run constraint validations on your data |
| FastAPI | Monitor your FastAPI models with WhyLabs |
| Feast | Learn how to log features from your Feature Store with Feast and whylogs |
| Flask | See how you can create a Flask app with this whylogs + WhyLabs integration |
| Flyte | Learn how to use whylogs' DatasetProfileView type natively on your Flyte workflows |
| Github Actions | Monitor your ML datasets as part of your GitOps CI/CD pipeline |
| MLflow | Log your whylogs profiles to an MLflow experiment |
| Sagemaker | Monitor your Amazon Sagemaker models with WhyLabs |
| ZenML | Combine different MLOps tools together with ZenML and whylogs |
AI
| Integration | Description |
|---|---|
| LangChain | Use LangKit to hook into LangChain and monitor your LLM applications |
| OpenAI | Use LangKit to log the prompts and responses from OpenAI's python api |
Others
| Integration | Description |
|---|---|
| whylogs Container | A low code solution to profile your data with a Docker container deployed to your environment |
| Java | Profile data with whylogs with Java |
Get in touch
Missing an important integration tool for your tech stack? Contact us at anytime!

