Databricks
By leveraging whylogs’ existing integration with Apache Spark, integrating whylogs with Databricks is simple.
Installing whylogs in Databricks
First, install the spark, whylabs, and viz modules from whylogs on the desired Spark cluster within Databricks:
whylogs[spark,whylabs,viz]
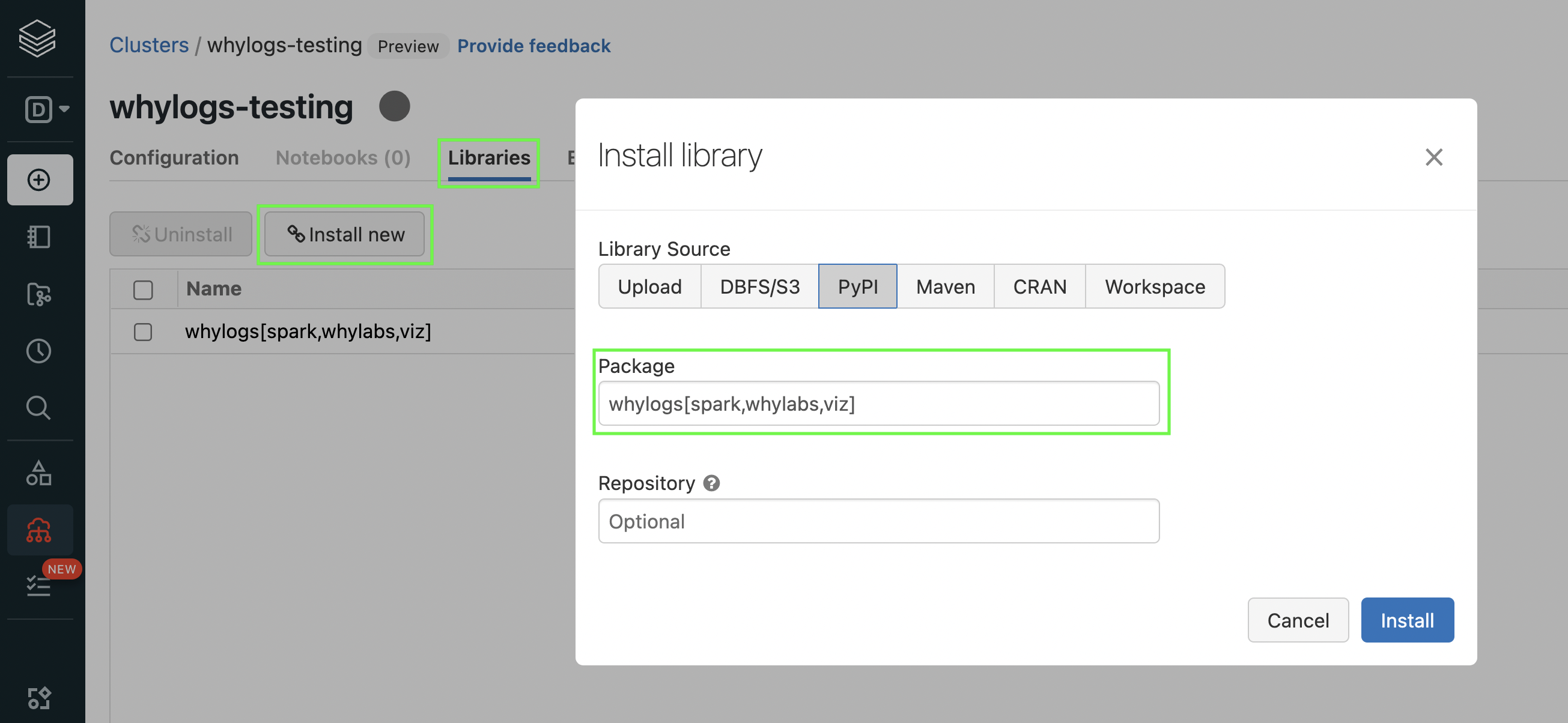
- The spark module enables users to profile Spark DataFrames with whylogs.
- The whylabs module enables users to upload these profiles to the WhyLabs AI Observatory.
- The viz module allows users to visualize one or more profiles directly in a Databricks notebook.
Profiling Data in Databricks
First, enable Apache Arrow.
arrow_config_key = "spark.sql.execution.arrow.enabled"
spark.conf.set(arrow_config_key, "true")
Next, read your data into a Spark DataFrame. This syntax will be different depending on how your data is stored.
df = spark.read.option("header", True).csv("dbfs:/FileStore/tables/my_data.csv")
Now, we profile the data and optionally view the result as a Pandas DataFrame.
from whylogs.api.pyspark.experimental import collect_dataset_profile_view
profile_view = collect_dataset_profile_view(df)
profile_view.to_pandas() #optional
From here, users may wish to build visualizations their profile directly in the Databricks notebook as demonstrated in this example notebook.
Uploading Profiles to WhyLabs
Users can upload this profile to WhyLabs using the following:
import os
os.environ["WHYLABS_DEFAULT_ORG_ID"] = "" #insert org id
os.environ["WHYLABS_API_KEY"] = "" #insert API key
os.environ["WHYLABS_DEFAULT_DATASET_ID"] = "" #insert dataset id
from whylogs.api.writer.whylabs import WhyLabsWriter
writer = WhyLabsWriter()
writer.write(file=profile_view)
For more on uploading profiles to WhyLabs, visit the Onboarding to the Platform page.
Notes on Versioning
The above assumes a whylogs version >= 1.0 and Spark cluster running a Pyspark version >= 3.0.
Users of Pyspark 2.x will need to use whylogs v0 and will need to load a JAR file specific to their Pyspark and Scala version. Please submit a support request for the appropriate JAR file if you are running a Spark cluster using Pyspark v2.x.

