Model Explainability
Maintaining explainability throughout a model’s life cycle is becoming increasingly important for running responsible ML applications. The WhyLabs AI Observatory makes this possible by helping you understand why and how a model is producing its output for both the global set of input data as well as for subsets of input data over time.
Enabling Explainability
Feature importance information can be supplied alongside with profile information. The user can choose the explainability technique that is most suitable for their use case.
Global Feature Importance
Global feature importance allows the user to understand which features have the strongest influence on a specific model’s output across an entire batch of input data. The default view of the explainability tab shows the global feature importance scores ranked by the absolute value of their weight.
Tracking global feature importance helps users prioritize features for monitoring and to better quantify the severity of any anomalies which may occur.
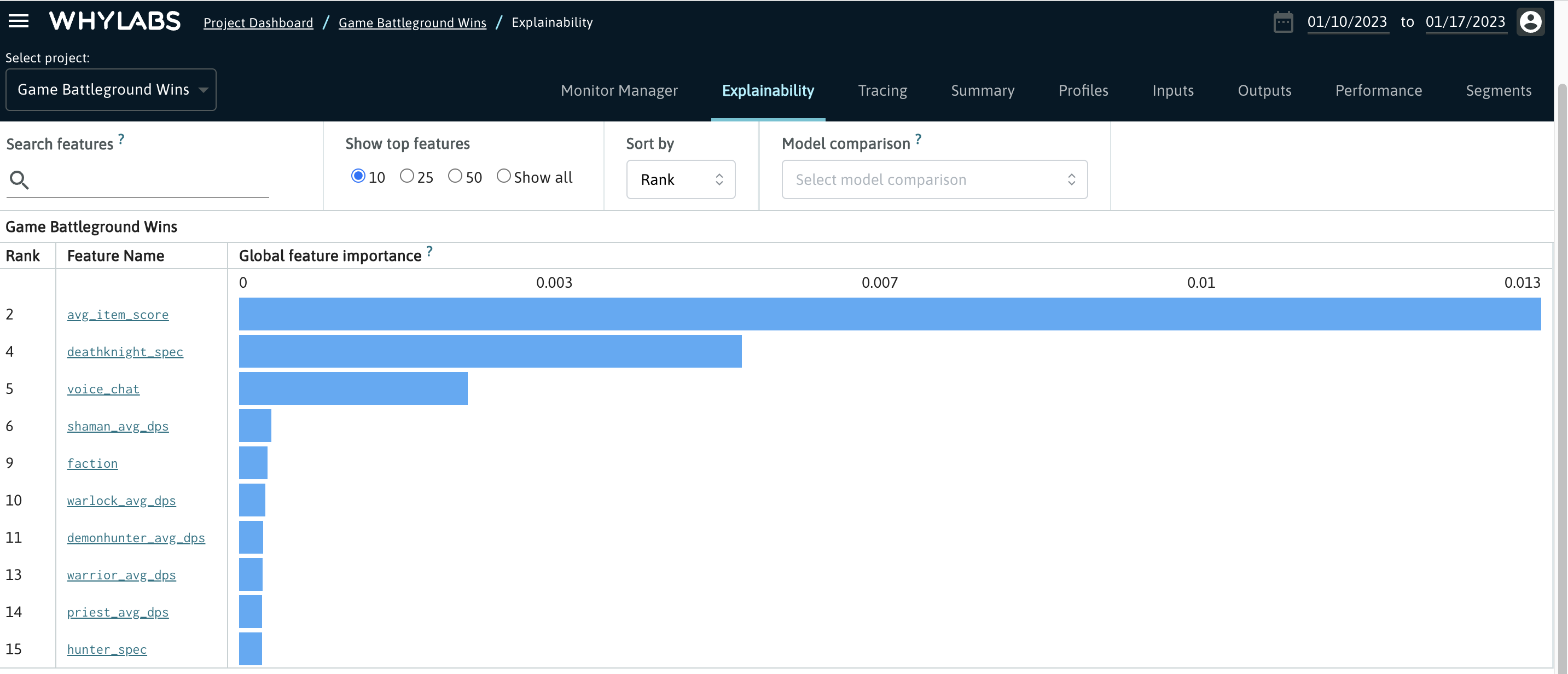
Sorting Features based on Importance
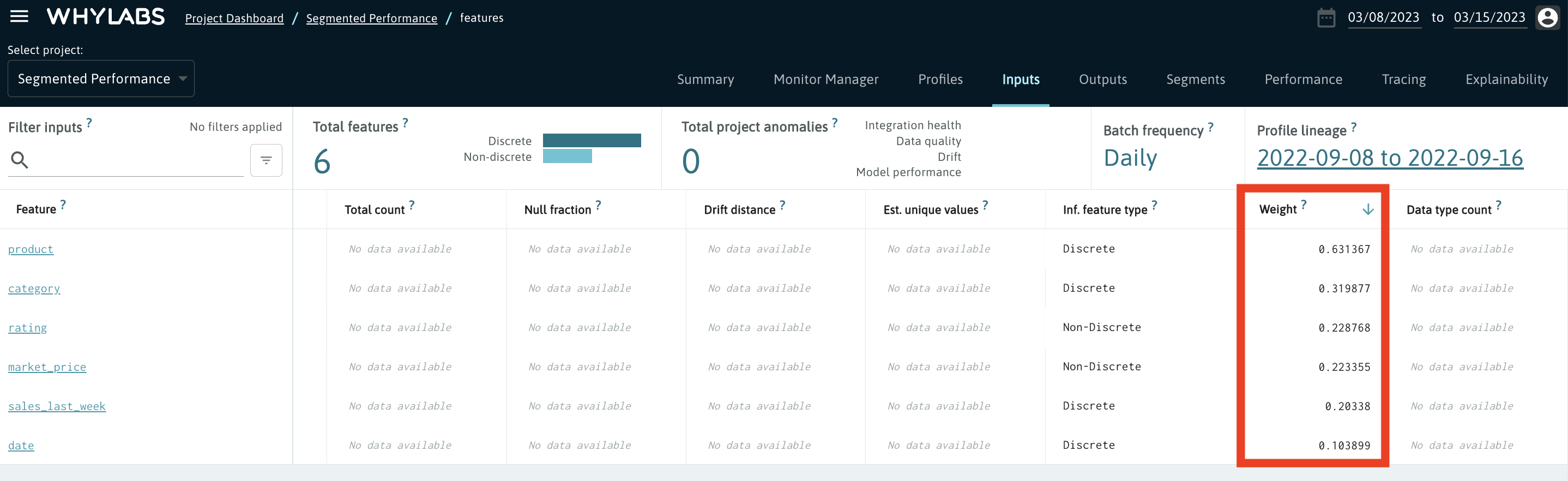
Once your features have importance scores assigned to them, you can sort them in the Inputs view according to these scores. Simply use the horizontal scroll bar to display the Weight column and click on the arrow to apply the sorting - see the screenshot below that depicts that.
Segment (Cohort) Feature Importance [coming soon]
ML practitioners are often interested in understanding feature importances for individual subsets of data and how these differ at the segment level. whylogs allows users to define segments when profiling a dataset, which enables this level of observability within the WhyLabs platform.
As an example, tracking feature importance at the segment level can reveal important differences in the influence that various input features have on a model’s output for users from different geographic regions. This can also reveal biases in our model which we want to avoid and help ML practitioners determine whether intervention is required.
Comparing Feature Importance across Different Models
Comparing feature importance between different models can help users examine how relative feature importance has changed following the retraining of a model. These changes may offer valuable insights which influence how features are prioritized when monitoring, how severity levels are assigned, or how users segment their profiles upon uploading.
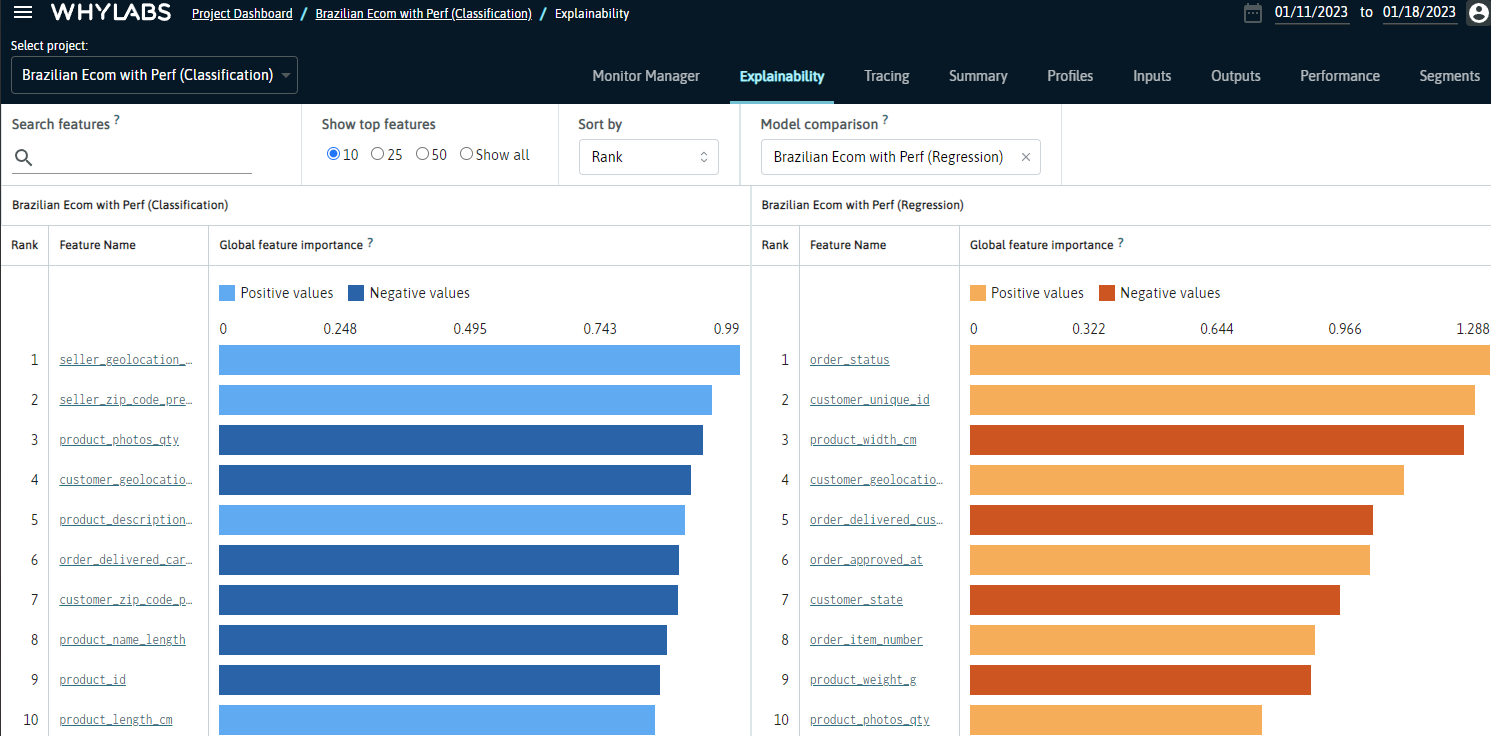
Monitoring Powered by Explainability
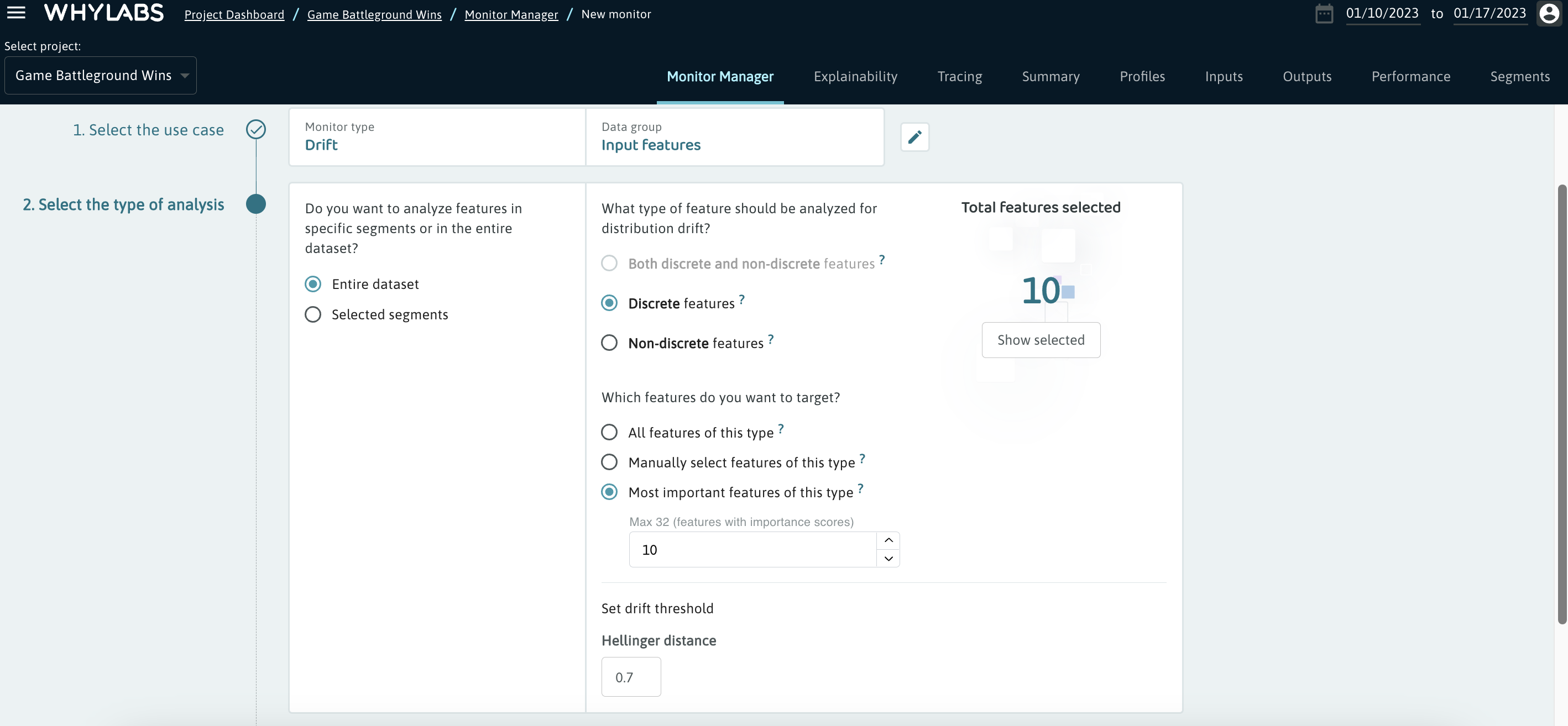
WhyLabs automatically classifies the most important features as “critical features”, allowing users to easily target them during monitor configuration. The recommended approach is to set up monitors of higher severity to detect changes in the most important features or to only limit notifications to those critical features to optimize the amount of alerts received.
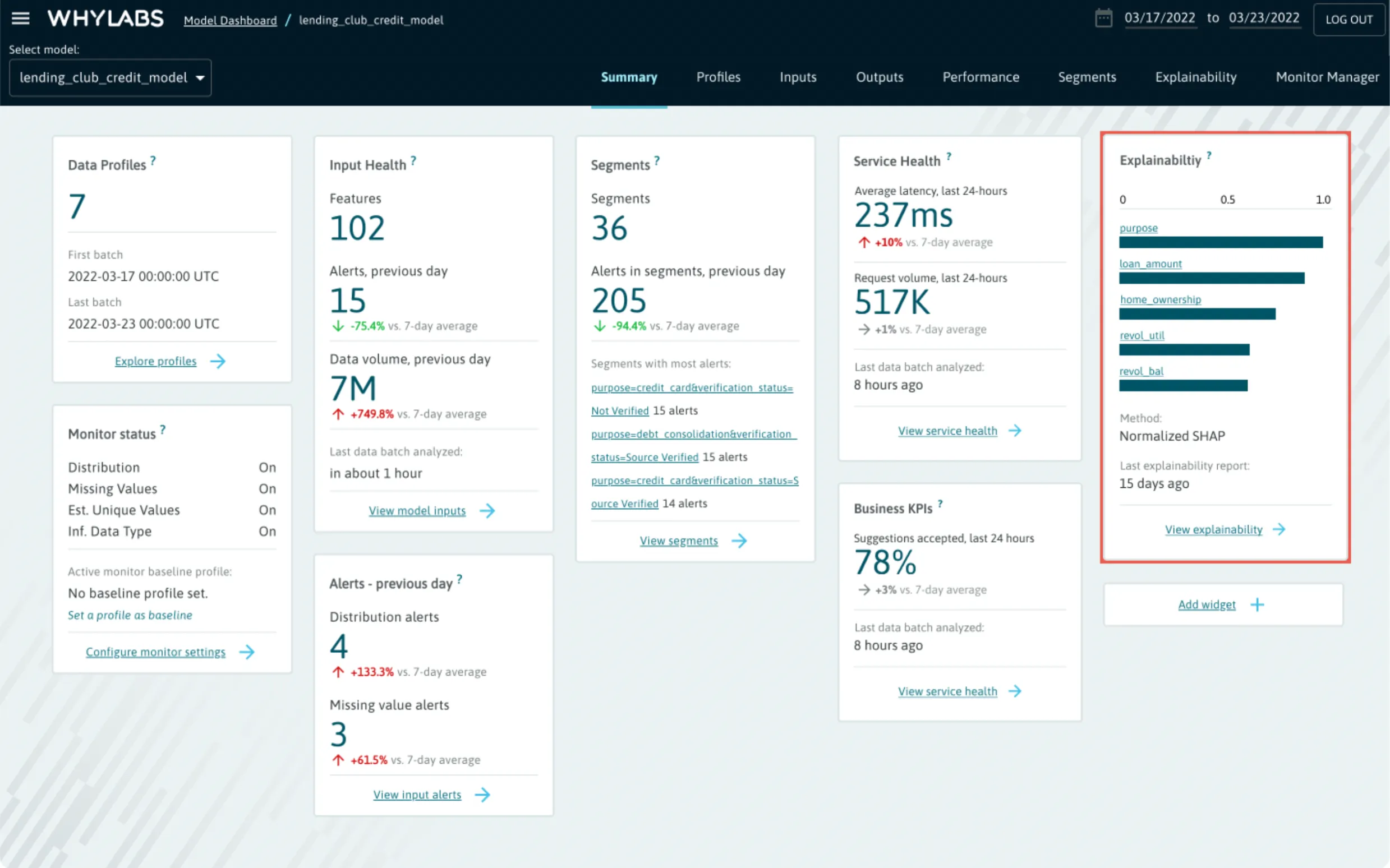
Explainability Summary Card
The critical features are displayed as part of a model’s summary, allowing users to maintain visibility into the features which have the most influence on the model’s behavior.
Debugging Powered by Explainability
As detailed above, maintaining explainability enables powerful model debugging capabilities. These include:
- Identifying bias in a model
- Understanding the impact of drift on model behavior
- Uncovering differences in model behavior for various data segments
- Informing decisions about model architecture (segments with significantly different feature importances may require different models)
- Identifying most important features to monitor and determining severity of notifications
- Feature weights can be the basis of further feature selection processes - removing unnecessary features could improve the maintainability and performance of your model.
Uploading the Feature Importance Scores
This section describes how to calculate some simple feature weights with a linear regression model and send those feature scores to WhyLabs.
The full code is available as a Jupyter Notebook here.
Installing Packages
First, let's make sure you have the required packages installed:
pip install whylogs[whylabs]
pip install scikit-learn==1.0.2
Setting the Environment Variables
In order to connect with the WhyLabs API, the following information has to be specified:
- API token
- Organization ID
- Dataset ID (or model-id) The Organization ID and the Dataset/Model ID are visible in the Summary view in the WhyLabs dashboard. The API token should be generated according to these instructions.
import getpass
import os
# set your org-id here - should be something like "org-xxxx"
print("Enter your WhyLabs Org ID")
os.environ["WHYLABS_DEFAULT_ORG_ID"] = input()
# set your datased_id (or model_id) here - should be something like "model-xxxx"
print("Enter your WhyLabs Dataset ID")
os.environ["WHYLABS_DEFAULT_DATASET_ID"] = input()
# set your API key here
print("Enter your WhyLabs API key")
os.environ["WHYLABS_API_KEY"] = getpass.getpass()
print("Using API Key ID: ", os.environ["WHYLABS_API_KEY"][0:10])
Calculating the Feature Weights
There are several different ways of calculating feature importance. One such way is calculating the model coefficients of a linear regression model, which can be interpreted as a feature importance score. That's the method we'll use for this demonstration. We'll create 5 informative features and 5 random ones. The code below was based on the article How to Calculate Feature Importance With Python, by Jason Brownlee. I definitely recommend it if you are interested in other ways of calculating feature importance.
from sklearn.datasets import make_regression
from sklearn.linear_model import LinearRegression
# define dataset
X, y = make_regression(n_samples=1000, n_features=10, n_informative=5, random_state=1)
# define the model
model = LinearRegression()
# fit the model
model.fit(X, y)
# get importance
importance = model.coef_
# summarize feature importance
weights = {"Feature_{}".format(key): value for (key, value) in enumerate(importance)}
weights
# output:
{'Feature_0': -3.330399790430435e-15,
'Feature_1': 12.44482785538977,
'Feature_2': -4.393883142916863e-14,
'Feature_3': -2.7047779443616894e-14,
'Feature_4': 93.32225450776932,
'Feature_5': 86.50810998606804,
'Feature_6': 26.746066698034504,
'Feature_7': 3.285346398262185,
'Feature_8': -2.7795267559640957e-14,
'Feature_9': 3.430594380756143e-14}
We end up with a dictionary with the features as keys and the respective scores as values. This is an example of global feature importance, as opposed to local feature importance, which would show the contribution of features for a specific prediction. Currently, WhyLabs and whylogs support only global feature importance. Therefore, this is the structure we'll use to later send the feature weights to WhyLabs.
Uploading the Feature Scores
The most straightforward way to send feature weights to WhyLabs is through whylogs, which is the method shown in this example.
We first need to wrap the dictionary into a FeatureWeights object:
from whylogs.core.feature_weights import FeatureWeights
feature_weights = FeatureWeights(weights)
And then use the WhyLabsWriter to write it, provided your environment variables are properly set:
from whylogs.api.writer.whylabs import WhyLabsWriter
result = feature_weights.writer("whylabs").write()
result
# output:
(True, '200')
Accessing the Feature Importance Scores
You can also get the feature weights from WhyLabs with get_feature_weights():
result = WhyLabsWriter().get_feature_weights()
print(result.weights)
# output:
{'Feature_4': 93.32225450776932, 'Feature_5': 86.50810998606804, 'Feature_6': 26.746066698034504, 'Feature_1': 12.44482785538977, 'Feature_7': 3.285346398262185, 'Feature_2': -4.393883142916863e-14, 'Feature_9': 3.430594380756143e-14, 'Feature_8': -2.7795267559640957e-14, 'Feature_3': -2.7047779443616894e-14, 'Feature_0': -3.330399790430435e-15}
print(result.metadata)
# output:
{'version': 28, 'updatedTimestamp': 1664373654215, 'author': 'system'}
As you can see, the result will contain the set of weights in result.weights, along with additional metadata in result.metadata.
If you write multiple set of weights to the same model at WhyLabs, the content will be overwritten. When using get_feature_weights(), you'll get the latest version, that is, the last set of weights you sent. You're able to see which version it is in the metadata, along with the timestamp of creation.

