Start Here
What is the WhyLabs AI Control Center
The WhyLabs AI Control Center allows you to monitor your data pipelines and machine learning models in production. If you deploy an ML model but don’t have visibility into its performance, you risk doing damage to your business, due to model degradation resulting from issues such as data or concept drift, data corruption, schema changes, and more.
In addition to observability and monitoring, the platform provides an extensive set of capabilities for LLM security and optimization workflows. For this reason, we've chosen to organize the platform around three sets of capabilities: Observe, Secure, and Optimize. While some features are common to all three, each is designed to address a specific set of use cases.
WhyLabs architecture at a glance
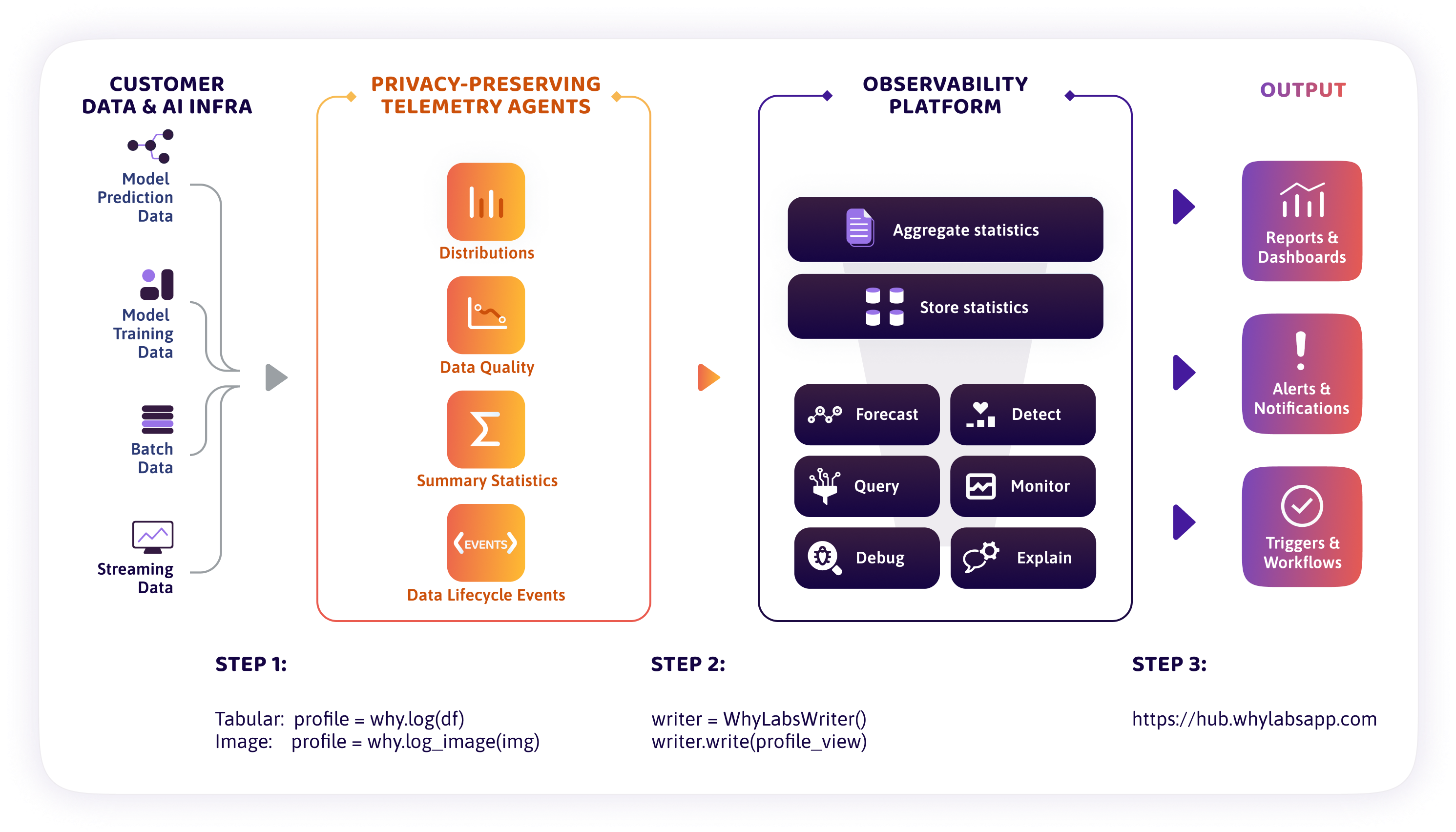
The WhyLabs AI Control Center is a hybrid SaaS, consisting of two major components:
- Telemetry agents: open source libraries that deploy directly into the user environment. These libraries collect privacy-preserving telemetry data that describes the health of models and datasets.
- Platform: the hosted platform that operates on the telemetry data generated by the agents. The platform offers a rich user interface for visualizing model and data health, configuring and detecting issues, and sending alerts.
The platform operates on the telemetry data generated by the agents. In addition to a rich, customizable user interface for visualizing model and data health, users of the platform can also configure alerts to detect issues and notifications to receive from the platform, as well as customize protective guardrails.
WhyLabs can also be deployed into a non-default VPC. Contact our team if you are interested in a custom VPC deployment.
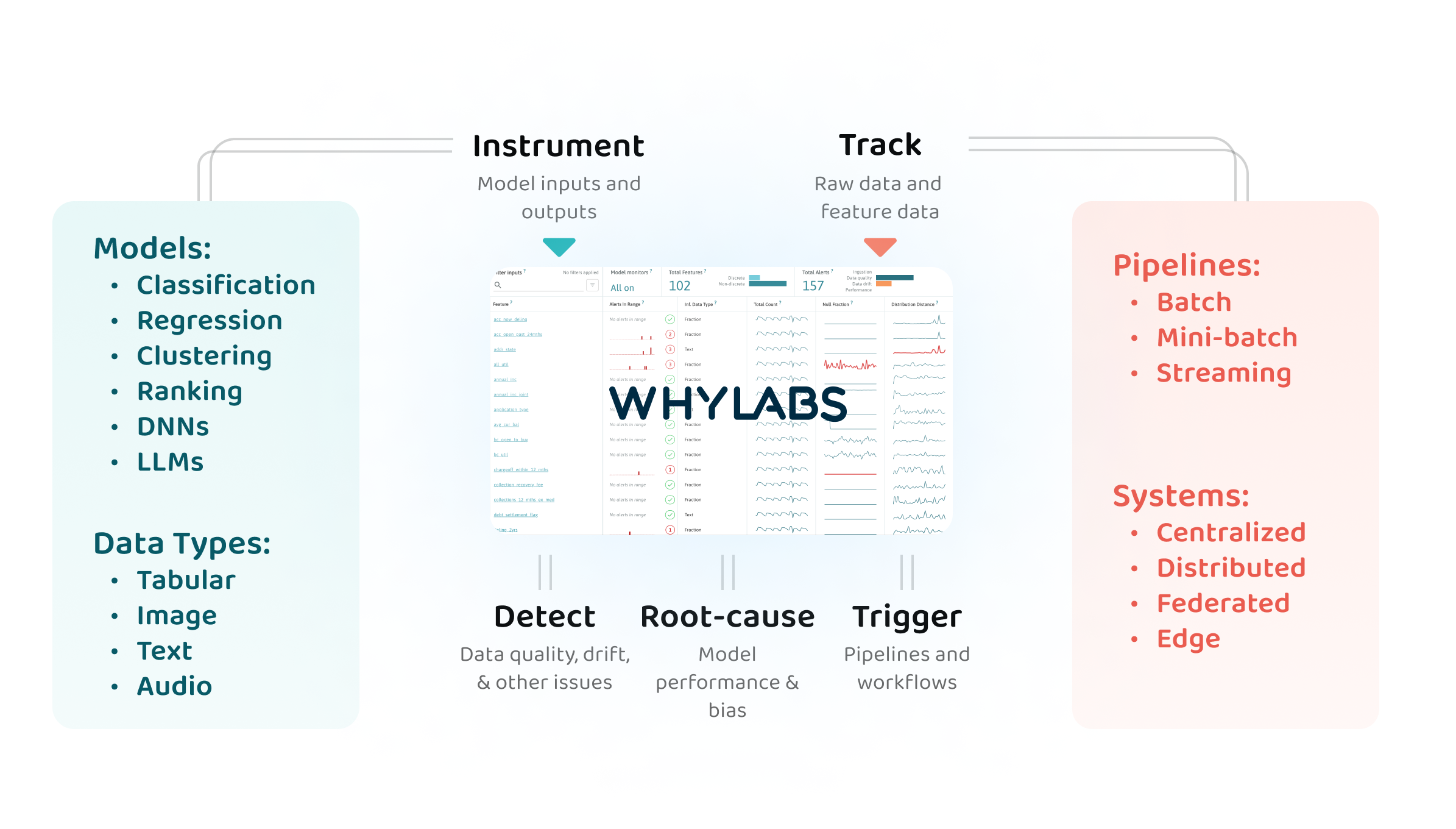
What does WhyLabs monitor?
WhyLabs AI Control Center enables monitoring for a wide range of use cases:
- Predictive ML models: all of the common ML model types
- Generative AI models: language models and LLMs
- Data in motion: Model inputs, feature stores, streaming and batch data pipelines
- ML features and feature stores: tabular data, text, images, and audio
How does WhyLabs secure and protect GenAI application?
WhyLabs AI Control Center provides several features to secure and protect your AI applications:
- Guardrail LLMs using our containerized secure agent and private policy manager
- Track LLM trace metrics over time, identify and block vulnerabilities, and optimize performance
- Visualize and debug LLMs interactions, including RAG events, using OpenLLMTelemetry
- Execute control across five critical dimensions: protection against bad actors, misuse, bad customer experience, hallucinations, and costs
Data profiling telemetry agents
WhyLabs relies on two open source telemetry agents—whylogs and LangKit—to create statistical snapshots of the data flowing through any AI system. These snapshots are called data profiles.
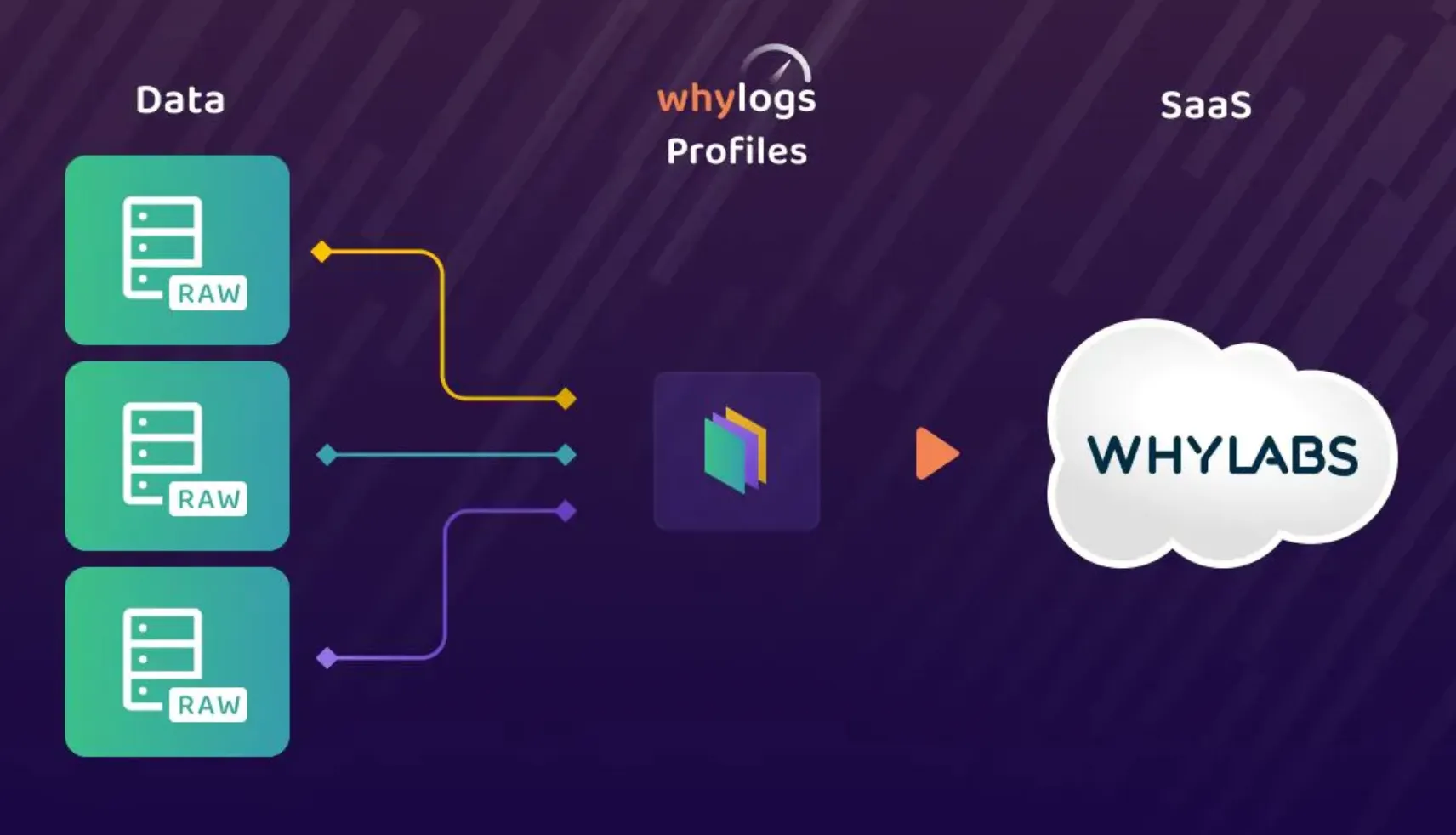
The data profiling agents enable monitoring of and observability at scale, and are designed to be lightweight, privacy-preserving, and scalable.
Data profiling with WhyLabs is a better strategy than working with raw data in order to monitor ML models and datasets:
- Privacy: WhyLabs won't ever ask users for raw data, as it only cares about the statistical values which can indicate potential anomalies
- Cost effectiveness: WhyLabs' data profiles are lightweight and it will only store the amount of information that is actually needed to monitor your data.
- Scalability: Data profiles are mergeable in any order, which opens ways for
MapReduceoperations on larger scales of data, leveraging Big Data technologies such as Ray, Apache Spark, Beam, etc. - No sampling required: work with 100% of the data with confidence, knowing than no outliers will be missed as a result of sampling
Profiles generated by the open source whylogs library to monitor the data flowing through your pipeline or being fed to your model.
For language models WhyLabs relies on LangKit to extract LLM and NLP specific telemetry. These profiles allow you to monitor the performance of your ML models, as they can capture prediction metrics.
Profiles created via whylogs or LangKit contain a variety of statistics describing your dataset and vary depending on whether you’re profiling tabular data, text data, image data, etc. These profiles are generated locally so your actual data never leaves your environment. Profiles are uploaded to the WhyLabs AI Control Center via API which provides extensive monitoring and alerting capabilities right out-of-the-box.
The WhyLabs approach to AI observability and monitoring is based on cutting edge research. Flexibility is a priority and the platform provides many customizable options to enable use-case-specific implementations.
To read more about WhyLabs, check out the WhyLabs Overview
What is whylogs
whylogs is the open source standard for profiling data. whylogs automatically creates statistical summaries of datasets, called profiles, which imitate the logs produced by other software applications.
The library was developed with the goal of bridging the data logging gap by providing profiling capabilities to capture data-specific logs. whylogs profiles are descriptive, lightweight, and mergeable, making them a natural fit for data logging applications. whylogs can generate logs from datasets stored in Python, Java, or Spark environments.
To read more about whylogs, check out the whylogs Overview
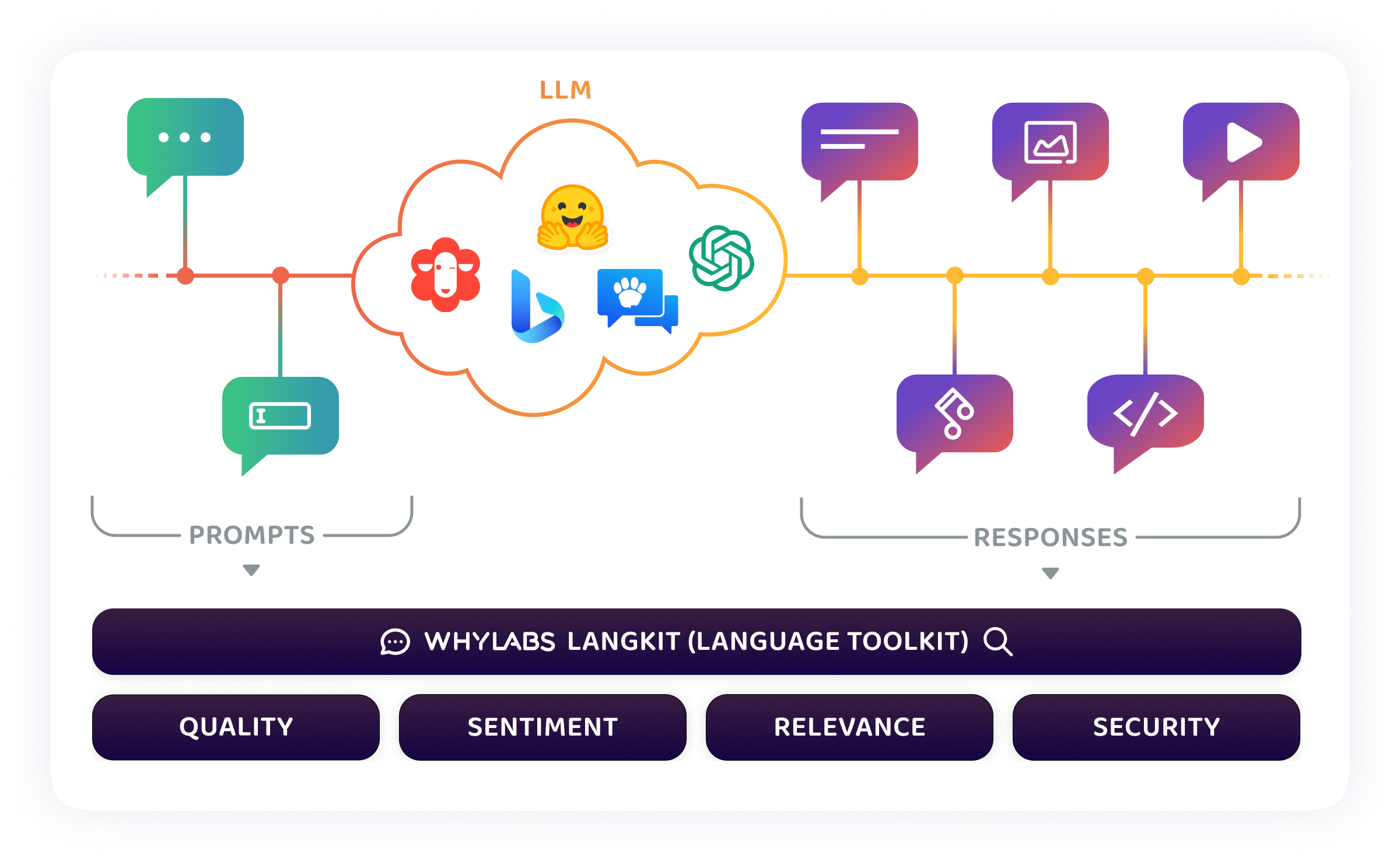
What is LangKit
LangKit is designed for language models. LangKit provides out-of the box telemetry from the prompts and responses of LLM to help you track critical metrics about quality, relevance, sentiment, and security. LangKit is designed to be modular and extensible, allowing users to add their own telemetry and metrics.
To read more about what you can do with LangKit, check out the LLM overview.
How to Navigate These Docs
Our documentation contains conceptual explanations, technical specifications, and tutorials.
In the WhyLabs AI Control Center section, you'll find technical specifications of the WhyLabs platform, as well as some conceptual explanations of its features.
In the Observe section, you'll find in documentation covering the platform's observability and monitoring capabilities.
In the Secure section, you'll find in documentation covering the platform's LLM security and guardrail capabilities.
In the Use Cases section, you'll find tutorials that walk you through how to do various things with whylogs and WhyLabs, such as generating profiles or checking data quality.
In the Integrations section, you'll find more tutorials that specify how to integrate with various other DataOps and MLSecOps tools, such as MLFlow and Databricks.
In the WhyLabs API References section, you'll primarily find technical specifications of the WhyLabs client and toolkit, the LangKit and whylogs libraries, as well as some conceptual explanations of their features.
Resources
To learn more about WhyLabs:
- Read about us: Blog, Press
- Watch us: WhyLabs Youtube Channel
- Chat to us: Community Slack
- Follow us: LinkedIn, Twitter
- Meet with us: Book a demo

