whylogs v1 Migration Guide
Introduction
We are excited to announce a huge step forward for our open source whylogs library: the release of whylogs v1. This release includes many improvements including:
- Huge performance improvements for faster profiling of large datasets
- A simplified and more intuitive API
- Introduction of profile constraints for advanced data validation
- A notebook based profile visualizer for building dynamic reports
- A usability refresh that includes improved documentation and examples to get users up and running quickly.
This document will focus primarily on helping users seamlessly migrate from whylogs v0 to v1. See this document for more information on the differences between whylogs v0 and v1 and details on the various improvements.
Important Dates
A dev version of whylogs v1 is available as of May 24th, 2022. Users can try out this dev version by installing as follows:
pip install whylogs --pre
Users can also start experimenting with whylogs v1 right away by visiting this Google Colab Notebook.
whylogs v1.0.0 will become the default whylogs version on May 31st, 2022. Any users installing or upgrading whylogs as of May 31st will be installing v1.
Action Required
While this release represents an exciting milestone for the whylogs library, there are some important implications for current whylogs users. Most notably, whylogs v1 comes with a simplified and more intuitive API. This means that if you choose to upgrade to v1, code changes will be required. Furthermore, the changes described in this document will only be relevant for users of the Python implementation of whylogs (Python and PySpark). Similar improvements will be reflected in a later version of the Java implementation for Java/Scala users.
WhyLabs Users
No action is required for existing WhyLabs users until they are ready to migrate to whylogs v1. WhyLabs will continue to support profiles uploaded via whylogs v0 following the release of whylogs v1. If users have automatic library upgrades in place, they are recommended to disable these automatic upgrades to allow for a smooth transition to whylogs v1 by making the necessary code changes beforehand. Note that this document does not yet contain examples for uploading profiles to WhyLabs using whylogs v1 but this is coming soon!
Table of Contents
Migrating Your Code
The following examples can be used to upgrade your code from whylogs v0 to v1. Please submit a support ticket for any cases not covered in this document.
A glossary of whylogs concepts and data types has been included in this document for reference.
Note that all v1 examples use the following convention:
import whylogs as why
Logging a Dataset
The following code snippets compare the process of logging a dataset in whylogs v0 and v1.
from whylogs import get_or_create_session
import pandas as pd
session = get_or_create_session()
df = pd.read_csv("path/to/file.csv")
with session.logger(dataset_name="my_dataset") as logger:
#dataframe
logger.log_dataframe(df)
#dict
logger.log({"name": 1})
#images
logger.log_images("path/to/image.png")
import whylogs as why
import pandas as pd
#dataframe
df = pd.read_csv("path/to/file.csv")
results = why.log(pandas=df)
#dict
results = why.log({'column_a':1.0, 'column_b':2.0})
#image
#coming soon!
#extract the profile for viewing, tracking, or saving to disk
profile = results.profile()
In the above code, the log method returns a ProfileResultSet object which is assigned to the results variable. The profile method is then called on this result to return a DatasetProfile object which is assigned to the profile variable.
Note that whylogs v1 has no concept of a session. Also note that whylogs v1 uses a single “log” method for each data type.
Writing Profiles to Disk
In whylogs v0, the log methods will automatically write profiles to disk. This is not the case for whylogs v1. If we wish to write a profile to disk with whylogs v1, we can pass the profile to the write function as shown below:
why.write(profile,"profile.bin")
We can also read a profile from disk.
n_prof = why.read("profile.bin")
Message Format
When a dataset is logged using whylogs v0, an “output” folder is created which contains a collection of files representing the profile in different formats including protobuf, json, csv.
In whylogs v1, profiles written to disk are only stored as a protobuf file with a user-specified path.
If a user wishes to store a profile in the format of a flat csv file, they can extract a Pandas DataFrame from a profile and save it to disk as a csv.
prof_view = profile.view()
prof_df = prof_view.to_pandas()
prof_df.to_csv('profile.csv')
Here, the view method is called on the profile variable to return a DatasetProfileView object. The to_pandas method is then called on this DatasetProfileView object which returns a Pandas DataFrame. Finally, the DataFrame is saved to disk using the to_csv method from Pandas.
Note that the column names of the Pandas DataFrame returned by whylogs v1 to_pandas method are different from the column names used in the flat CSV files generated by whylogs v0. Furthermore, information regarding the cardinality and frequent items are also captured in this DataFrame rather than stored in different files.
Updating Profiles
In whylogs v0, profiles can be generated in a piecewise fashion by calling multiple log methods upon the same logger instance. The following code will automatically merge any profiles logged.
session = get_or_create_session()
with session.logger(dataset_name="my_dataset") as logger:
logger.log_dataframe(df1)
logger.log_dataframe(df2)
logger.log_dataframe(df3)
...
In whylogs v1, the track method can be called on an existing DatasetProfile instance to log new datasets and merge them with the existing profile.
results = why.log(pandas=df1)
profile = results.profile()
profile.track(pandas=df2)
profile.track(pandas=df3)
...
The profile variable above holds a DatasetProfile instance which represents a profile of the 3 combined datasets.
Log Rotation (Streaming)
whylogs supports log rotation which is especially useful for streaming use cases. Streamed data is being continuously read and processed by the logger instance. Users can define how often this profile is written to disk or to WhyLabs .
In the case of whylogs v0, the frequency of writing profiles to disk is determined by the with_rotation_time parameter. In the example below, profiles are written to disk once every 5 minutes.
from whylogs import get_or_create_session
session = get_or_create_session()
with session.logger(dataset_name="dataset", with_rotation_time="5m") as logger:
for record in stream.get_data():
logger.log(record)
In the case of whylogs v1, this is achieved via the following. In this case, the mode parameter indicates that log rotation will be used. The interval and when parameters indicate that profiles should be written to disk every 5 minutes.
import whylogs as why
with why.logger(mode="rolling", interval=5, when="M", base_name="test_base_name") as logger:
logger.append_writer("local", base_dir="whylogs_output")
for record in stream.get_data():
logger.log(row=record)
Profile Visualization
whylogs v0 contained a browser based profile visualization tool. Users can launch this tool with the following code and manually upload a profile’s json file to it:
from whylogs.viz import profile_viewer
profile_viewer()
After selecting the JSON file for upload, users would see something like the following.
whylogs v1 instead utilizes notebook based visualization capabilities. Instead of a single visualization tool, the Notebook Profile Visualizer offers a variety of dynamic visualization capabilities which includes the ability to compare reference and target profiles against each other.
First, users will need to install the viz module. This is done as a separate installation to keep the core whylogs library as lightweight as possible and minimize dependencies.
pip install "whylogs[viz]"
The following code initializes a Notebook Profile Visualizer object and sets reference and target profiles from two different datasets.
import whylogs as why
result = why.log(pandas=df_target)
prof_view = result.view()
result_ref = why.log(pandas=df_reference)
prof_view_ref = result_ref.view()
from whylogs.viz import NotebookProfileVisualizer
visualization = NotebookProfileVisualizer()
visualization.set_profiles(target_profile_view=prof_view, reference_profile_view=prof_view_ref)
From here, a number of different visualizations can be constructed to compare the target and reference profiles. One example is the Summary Drift Report.
visualization.summary_drift_report()
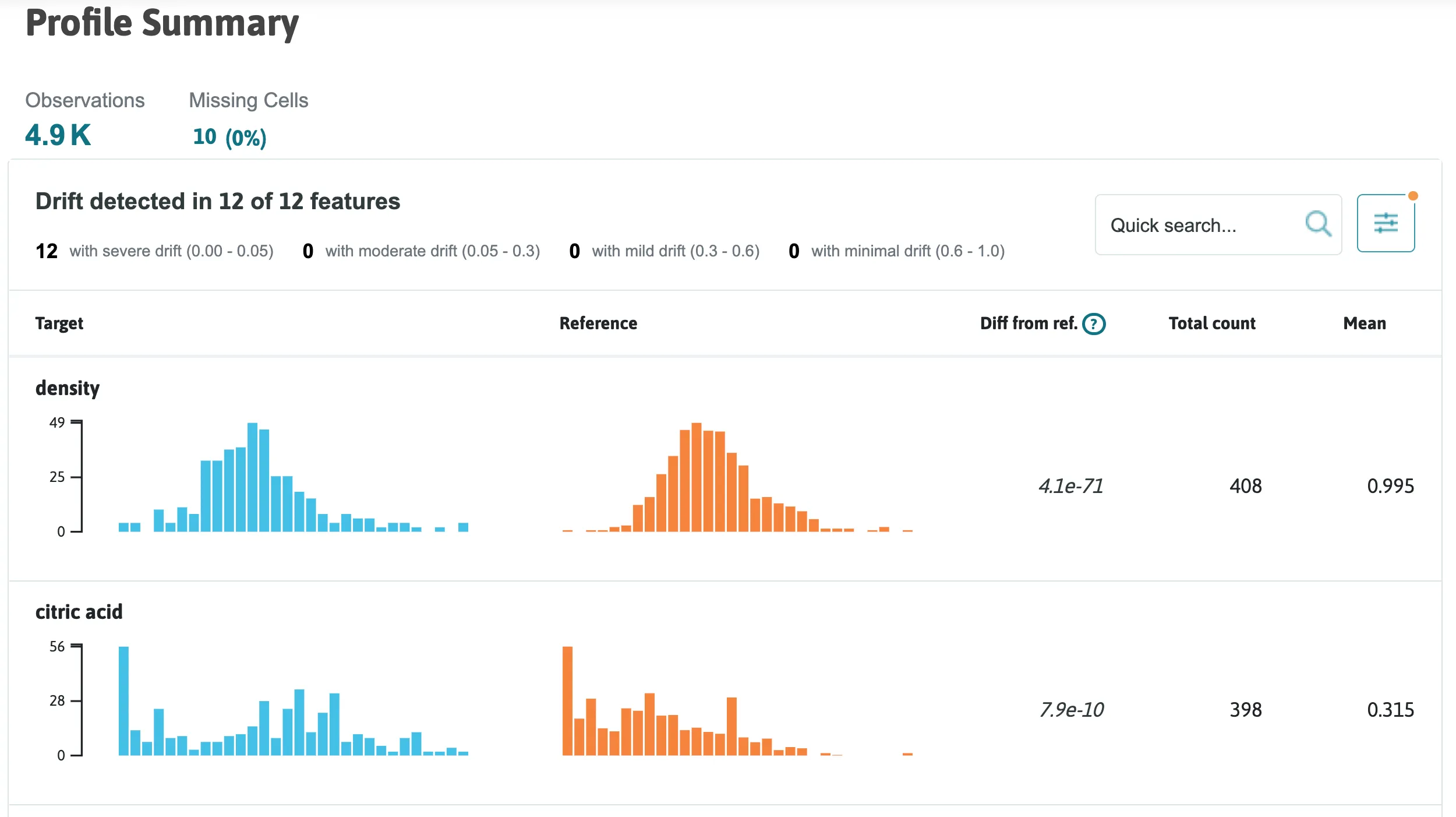
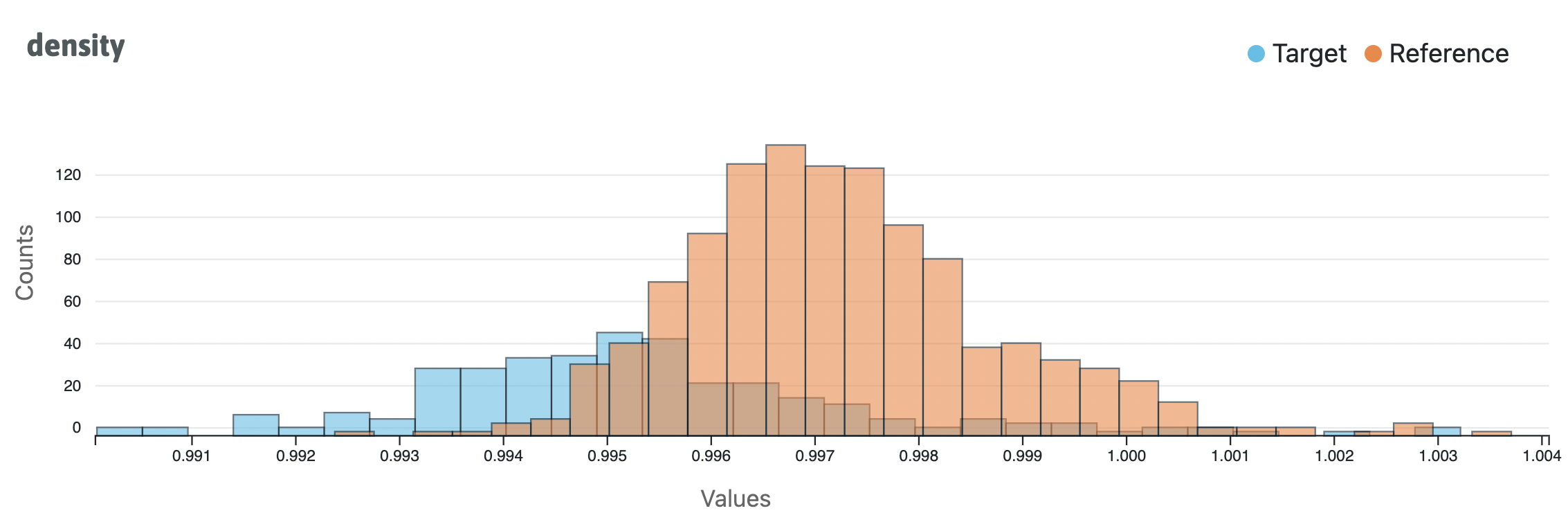
As another example, users can view overlapping histograms of two distributions for a particular feature.
visualization.double_histogram(feature_name="density")
Concepts
One of the priorities when creating whylogs v1 was a more intuitive user experience. New concepts were introduced to the whylogs v1 library with this goal in mind. The following is a glossary which summarizes these concepts and data types.
ResultSet - When passing a dataset to the log function, a ResultSet is returned. This ResultSet can contain either a single profile or multiple profiles (in the case of segmentation). With whylogs v1, there is just a single log function which handles each data type (Pandas DataFrame, Python dictionary, image, etc.).
ProfileResultSet - A ProfileResultSet is a subclass of ResultSet. When the log function returns a single profile, or when a single element of a ResultSet is retrieved, the result is a ProfileResultSet object. Users can call the profile method on this object to inspect or update the telemetric data captured in the profile or its metadata such as the dataset_timestamp. Users can also call the view method on a ProfileResultSet for a variety of visualization capabilities.
DatasetProfile - A DatasetProfile represents a collection of in-memory profiling stats for a dataset. An object of this class is returned when calling the profile method on a ProfileResultSet. The DatasetProfile has methods for accessing/updating the metadata associated with a profile, writing a profile to disk, generating a view of a profile, etc.
DatasetProfileView - A DatasetProfileView allows you to inspect your profiles in a human readable format. This object is returned when calling the view method on a ProfileResultSet or a DatasetProfile object. A DatasetProfileView has methods for returning a profile as a Pandas DataFrame, merging multiple DatasetProfileView objects together, reading/writing to disk, etc.
Writer - A Writer object is responsible for writing profiles to some location. There is a different type of Writer for each method of writing profiles (to local disk, uploading to WhyLabs, to MLFlow artifacts, etc.).
Coming soon!
The initial release of whylogs v1.0.0 will not support several features currently available in whylogs v0. The following features will be re-introduced in the release of whylogs v1.1.
- Logging images
- Uploading profiles to WhyLabs
- Segments
- Performance Metrics
- MLFlow Integration

