WhyLabs Secure
Secure: Guardrails for Safe and Reliable AI Applications
The following is a high level overview of the security features that can be enabled by the WhyLabs AI Control Center. These capabilities are grouped together under the "Secure" moniker.
The capabilities are made available as a result of our work to combine insights from a wide range of public sources, latest LLM security research and techniques, data from the LLM developer community, and from our Red Team.
About Secure
WhyLabs Secure acts as a robust set of capabilities that provide a shield for your AI, mitigating potential risks like hallucinations, data leakage, misuse, bad user experience, and inappropriate content generation.
Similar to all other models, LLMs that are onboarded to the platform have access all the Observe features: monitoring, explainability, segments, observability, performance dashboards/performance tracing, and more. Organizations have the option of adding an additional "Secure" capabilities to each LLM, to access a view of RAG data, traces, policy management, and more.
With Secure, both developers and security teams are empowered to confidently deploy and manage their AI applications.
- Developers: Safeguard your internally developed LLM applications, enabling confident deployment to production environments. Ensure your AI models operate as intended, free from unexpected behaviors or vulnerabilities.
- Security and data governance teams: Accelerate the adoption of AI within your organization by leveraging WhyLabs Secure to protect against risks associated with third-party AI tools like ChatGPT and Bard. By integrating with your existing security infrastructure, WhyLabs Secure provides an additional layer of defense against potential threats.
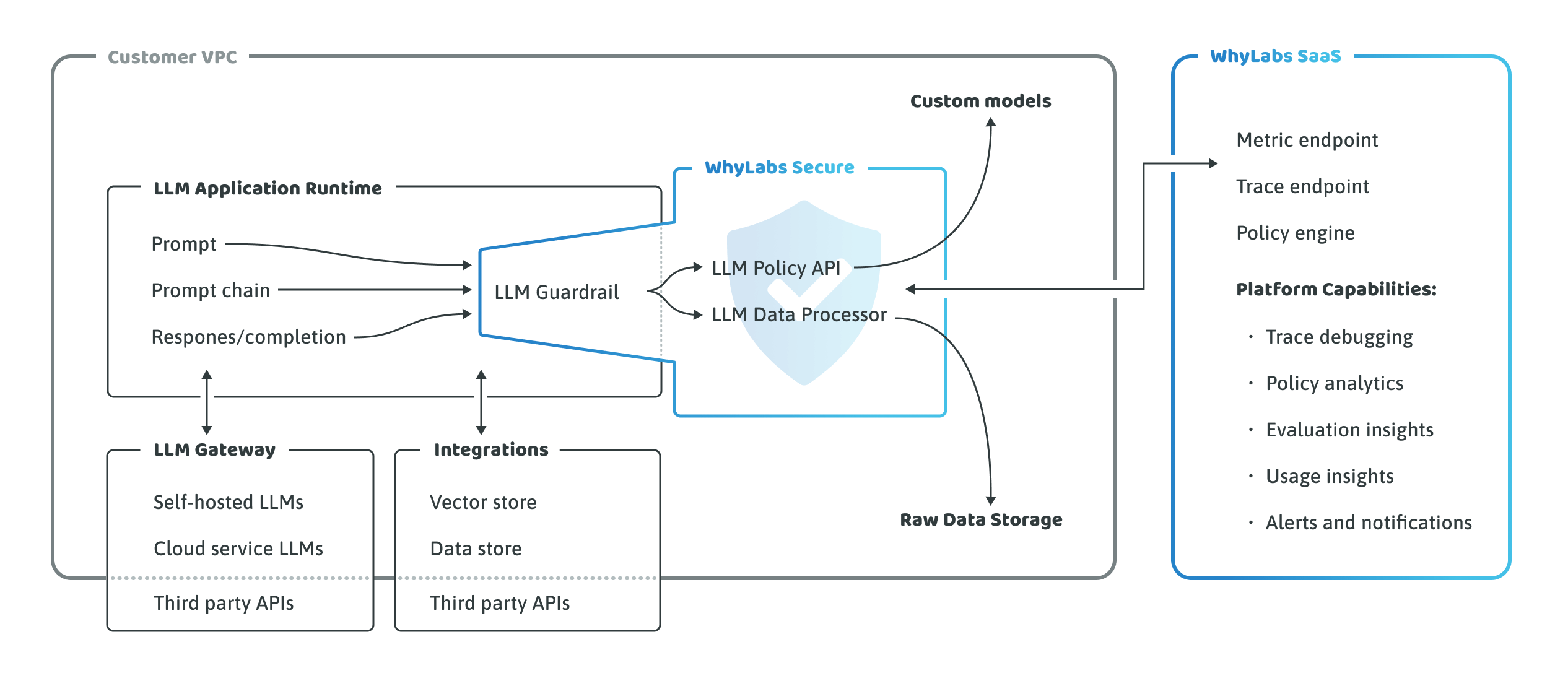
Secure requires a containerized agent to be securely deployed into the customer's VPC. This agent includes a dedicated policy API, with the policy itself managed from the WhyLabs AI Control Center. The policy provides easy-to-use LLM guardrails aligned to MITRE ATLAS and LLM OWASP standards.
Via a proprietary integration with OpenLLMTelemetry, the platform visualizes the emitted LLM traces, and provides insights via key metrics relating to blocked and flagged interactions.
How it works
WhyLabs Secure is a hybrid-SaaS with an on-prem component and a SaaS control plane that makes it simple and easy to deploy and operate.
How to enable Secure in the WhyLabs AI Control Center
You can start protecting your LLM applications in minutes by signing up for a free WhyLabs account at hub.whylabsapp.com. Then, follow our integration guide on the Getting Started page to onboard an LLM.
After you've done this you can request a free trial of Secure capabilities. Simply click on the "Get LLM Secure" button the platform to request a free 14 day trial:

More information on the Secure capabilities can be found in the Secure documentation.
Model compatibility
WhyLabs Secure is LLM-agnostic and works with:
- Any hosted model provider (OpenAI, Amazon BedRock, Anthropic Cohere, etc.)
- Any open-source model
- Your own custom models
WhyLabs Secure Features
The Secure capabilities of the platform are organized into three sections:
- A summary dashboard with visualizations of trace and policy metrics,
- A traces dashboard for deeper analysis of the trace event data emitted by the AI application, and
- A policy dashboard where the policy rulesets can be customized to fit the required security guardrails.
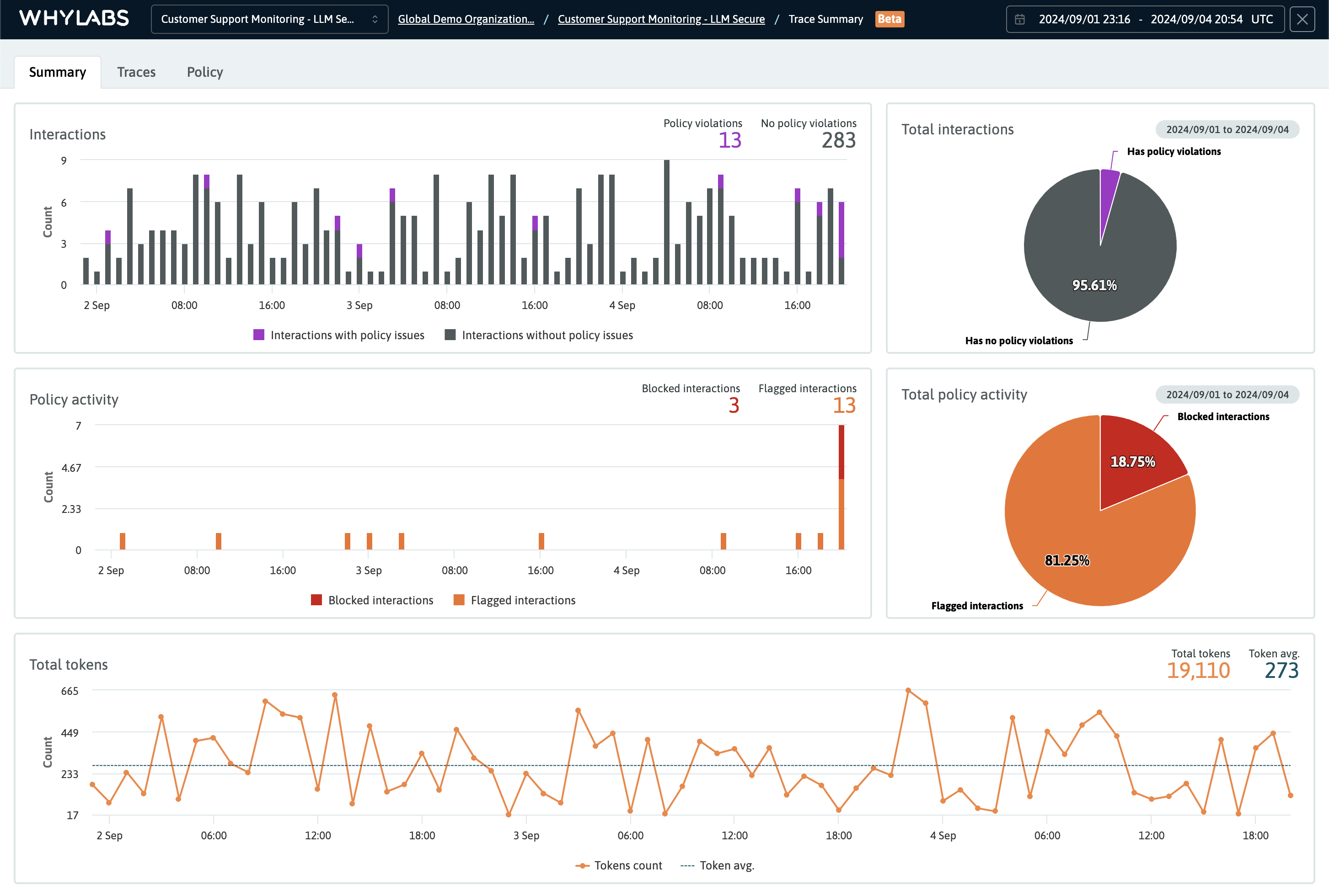
Summary Dashboard
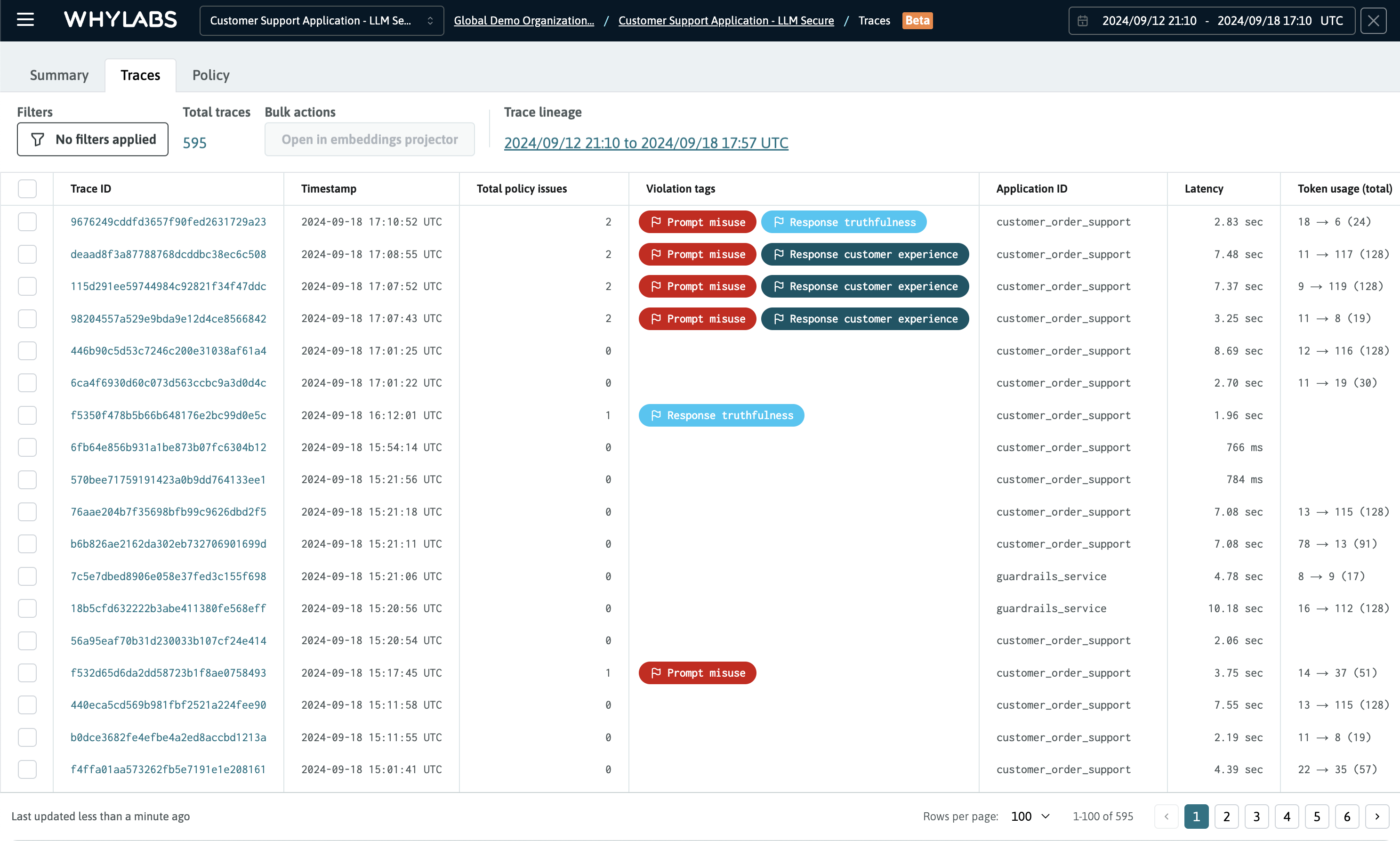
Traces Dashboard
Traces can be filtered by time ranges and analyzed as needed. Additional filters are provided for other dimensions including: tags type, latencies, model versions, and IDs.
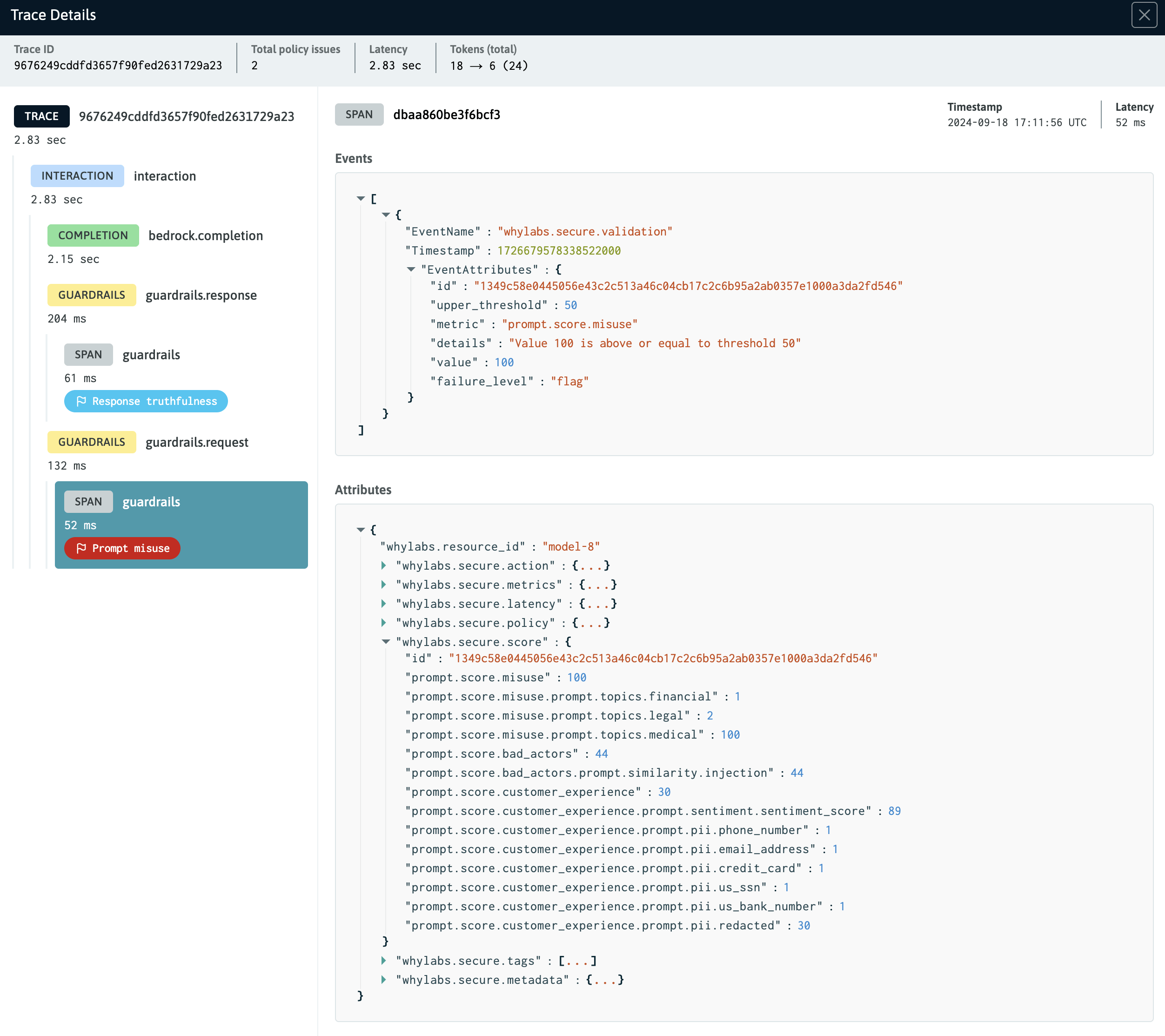
Trace Detail View
Traces allow for inspection and debugging of span event data emitted by the AI application in a "trace detail view", so that issues can be easily identified, evaluated, and subsequently mitigated.
Policy Dashboard
WhyLabs Secure provides five policy rulesets that can be enabled in 1-click via the Policy dashboard.
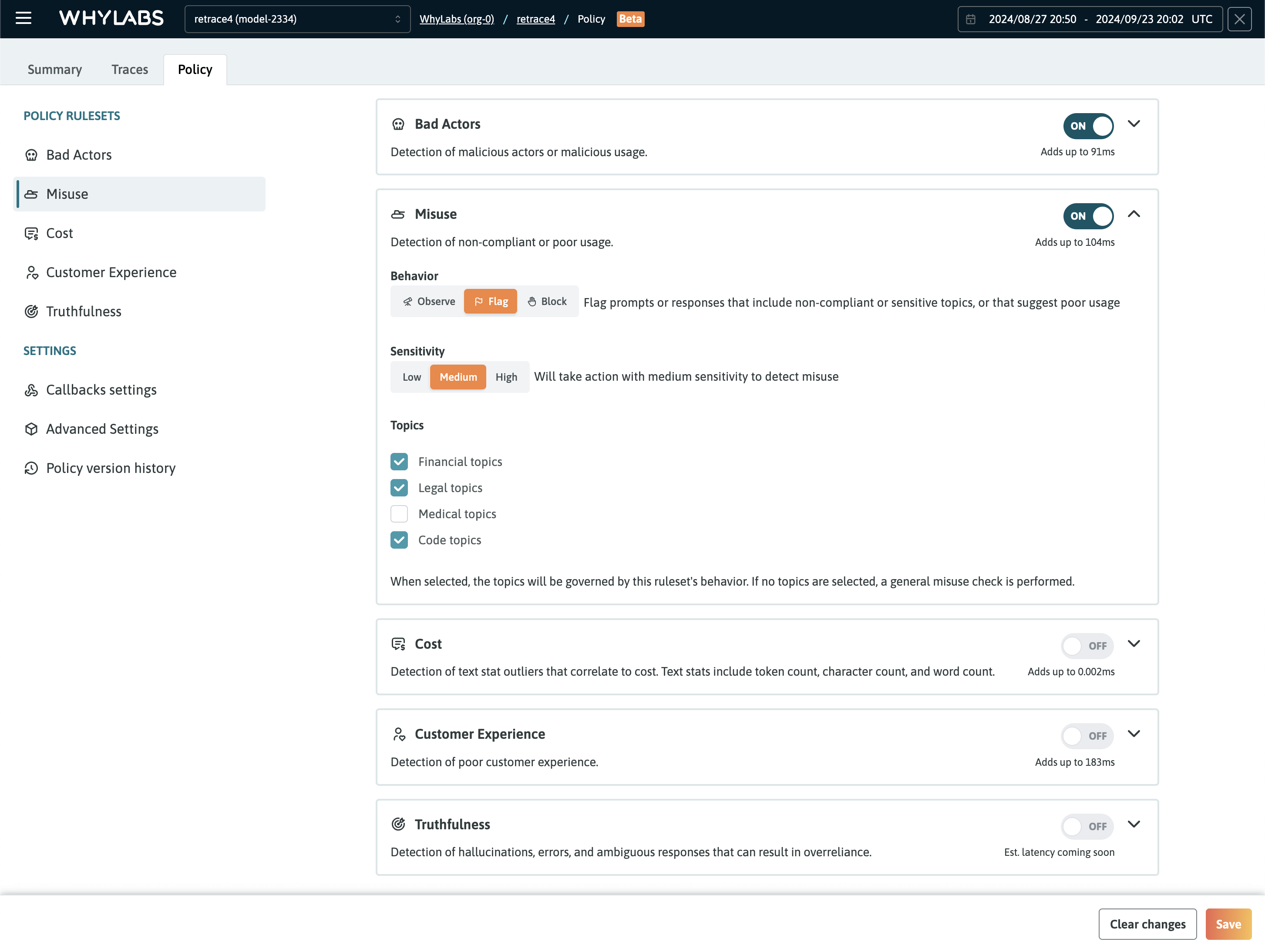
The rulesets cover important risk categories, offering fine-grained control when operating the AI application:
- Bad actors ruleset: detects prompts that include malicious actors or that indicate malicious usage
- Misuse ruleset: detects prompts or responses that include non-compliant or sensitive topics, or that suggest poor usage
- Cost ruleset: detects statistical outliers that correlate to cost including token count and character count
- Customer Experience ruleset: detects interactions that indicate the user had a poor customer experience with the AI application
- Truthfulness ruleset: detects hallucinations, errors, and ambiguous responses that can result in overreliance.
Each ruleset provides controls to either observe, flag, or block interactions that have violated the policy's settings. Each ruleset also provides a sensitivity configuration and additional options based on the ruleset. For example, it's possible to include specific topics that should be detected for the Misuse ruleset.

